optim()で階層構造を持った多変数の最適化をしてみる
最適化周りの処理について実装する必要が出たので,optim() を調べて使ってみましたよ,という話.
optim() って関数の形で表わせさえすれば,結構なんでも自由にできるっぽくて便利です.特に,階層的な構造を持ったデータの最適化もできるのは大きいです.
例
階層化ということで,ここで例に挙げるのは,比率の最適化です.イメージとしては,各クラスにおける学級委員長の選出を思い浮かべてもらえればと思います.
各クラスには複数の立候補者がいて,その支持率が既知のものとします*1.各クラスの生徒に対して,支持している候補者と,目指すクラスの方向性についてのアンケート聞いたとしてください.その得られたアンケート結果に対しなにがしかの係数をかけて,各立候補者の支持スコアを算出します.で,それを全立候補者のスコア合計で割ってあげれば,各立候補者の支持率が擬似的に出せます.
そうすると,クラスごとに算出した支持率と,実際の支持率の両者が得られます.アンケート結果にかける係数を調整することで,支持率の予測と実際の乖離を0に近づけましょう,ということになります.この場合,係数がかかるのは各クラスの生徒ですが,知りたいのはクラスごとの支持率という,クラス単位のパラメタだという階層構造になるわけです.
サンプルデータの作成
とりあえず,以下のようにクラスデータを作っておきます.わかりやすくするために,クラスは2つ,各クラスの候補者も2人としておきます.ここでポイントは,予め各候補者のカラムを作っておくことです.各生徒の支持対象はわかっているので,ここでは1または0の値で表しちゃいます*2.
library(dplyr) # 選択肢1, 2のデータを作成して結合 # 項目は以下の通り # クラス番号 # 候補者1支持ダミー # 候補者2支持ダミー # 価値観1 # 価値観2 location1 <- matrix(c(rep(1, 100), rep(1, 30), rep(0, 70), rep(0, 30), rep(1, 70), rep(1, 71), rep(0, 29), rep(0.3, 69), rep(0.7, 31)), 100, 5) location2 <- matrix(c(rep(2, 100), rep(1, 50), rep(0,50), rep(0, 50), rep(1,50), rep(0.1, 40), rep(0.8, 20), rep(0.5, 40), rep(0.2, 20), rep(1, 80)), 100, 5) d <- as.data.frame(rbind(location1, location2)) colnames(d) <- c("class_id", "person1", "person2", "value1", "value2") # クラス1, 2の支持率データ # 項目は以下の通り # クラス番号 # 候補者1支持率 # 候補者2支持率 s <- as.data.frame(t(matrix(c(1, 0.8, 0.2, 2, 0.6, 0.4), 3, 2))) colnames(s) <- c("class_id", "support1", "support2") # 結合してデータセットを作成 ds <- d %>% inner_join(s, by="class_id")
最適化対象の関数の作成
やりたいのは各候補者のスコアを出して,それを既知の支持率と比較することです.まずはわかりやすくするために,1クラス分のデータだけでやってみたいと思います.
# 1クラスぶんにデータを絞る ds1 <- ds %>% filter(class_id==1) # 最適化する関数 predict_rating <- function(b, d, print=FALSE) { d_tmp <- d d_tmp$predict1 <- b[1]*d_tmp$person1*b[3]*d_tmp$value1*b[4]*d_tmp$value2 d_tmp$predict2 <- b[2]*d_tmp$person2*b[3]*d_tmp$value1*b[4]*d_tmp$value2 # クラスidでグループ化して合計スコアを出した上で,比率に変換する d_tmp2 <- d_tmp %>% group_by(class_id, support1, support2) %>% summarize(., predict1=sum(predict1), predict2=sum(predict2)) total <- d_tmp2$predict1+d_tmp2$predict2 d_tmp2$predict1 <- d_tmp2$predict1/total d_tmp2$predict2 <- d_tmp2$predict2/total if (print) { print(d_tmp2) } # 最少化する関数は二乗誤差 sum((d_tmp2$support1-d_tmp2$predict1)^2+abs(d_tmp2$support2-d_tmp2$predict2)^2) }
optim() で実行
ここまで用意ができたら,実際にoptim() で実行します.この場合,最適化したい係数は非負で一定の範囲の実数に抑えたいとします.そのような指定ができる手法は,どうやら "L-BFGS-B*3" だけらしいので,これを選択します.各変数は0から10の範囲を取るという制約を与えます*4.各係数の初期値には,平均と分散が1の正規分布から乱数を生成し,負の値は正にするかたちで用いています.
res <- optim(abs(rnorm(4, 1, 1)), predict_rating, d=ds1, method="L-BFGS-B", lower=0, upper=10, control=list(maxit=10000)) res
これを実行すると,以下のように結果が得られ,実際に最適化がなされていることが見て取れます.
> res <- optim(abs(rnorm(4, 1, 1)), + predict_rating, + d=ds1, + method="L-BFGS-B", + lower=0, + upper=10, + control=list(maxit=10000)) > res $par [1] 3.2007261 0.5497433 0.5569501 0.7339547 $value [1] 1.603087e-14 $counts function gradient 10 10 $convergence [1] 0 $message [1] "CONVERGENCE: REL_REDUCTION_OF_F <= FACTR*EPSMCH" > predict_rating(res$par, d=ds1, TRUE) Source: local data frame [1 x 5] Groups: class_id, support1 [?] class_id support1 support2 predict1 predict2 (dbl) (dbl) (dbl) (dbl) (dbl) 1 1 0.8 0.2 0.7999999 0.2000001 [1] 1.603087e-14
ここまで結果が得られたところで,最適化対象のクラス数を2にしてみましょう.ds1ではなくdsを使う,というだけですが.そうすると,見事に以下のように最適化された結果が得られています.もちろん2クラスに同じ係数を当てはめているため,クラス1については当てはまりが多少悪くなっています.それでもクラス1,2ともにそれなりによい当てはまりになっていることがわかるかと思います.
> res <- optim(abs(rnorm(4, 1, 1)), + predict_rating, + d=ds, + method="L-BFGS-B", + lower=0, + upper=10, + control=list(maxit=10000)) > res $par [1] 2.42237544 0.52544405 1.42063132 0.04326498 $value [1] 0.005155603 $counts function gradient 8 8 $convergence [1] 0 $message [1] "CONVERGENCE: REL_REDUCTION_OF_F <= FACTR*EPSMCH" > predict_rating(res$par, d=ds, TRUE) Source: local data frame [2 x 5] Groups: class_id, support1 [?] class_id support1 support2 predict1 predict2 (dbl) (dbl) (dbl) (dbl) (dbl) 1 1 0.8 0.2 0.7600352 0.2399648 2 2 0.6 0.4 0.6313148 0.3686852 [1] 0.005155603
glmnetで正則化を試してみる
タイトルの通り,よく考えたら今までL1/L2正則化を知識としては知ってるけど,実際に試したことはなかったことに気がついたので試してみましたよという話.L1/L2正則化にの理屈については,TJOさんのエントリとか,unnounnoさんのエントリとかをみてもらえれば良いのではと思います.それより詳しいことが知りたければ,PRMLでも読めば良いのではないでしょうか(適当*1).
まずはデータを眺める
使用したデータは,caretパッケージのcarsパッケージです*2.中古車販売のデータっぽくて,価格と,走行距離とか気筒とかドア数とかの車に関するカラムが並んでます.データを読み込んで,可視化して,とりあえず lm() してみます.
> library(glmnet) > library(caret) > library(psych) > > # load data > data(cars) > t(head(cars)) 1 2 3 4 5 6 Price 22661.05 21725.01 29142.71 30731.94 33358.77 30315.17 Mileage 20105.00 13457.00 31655.00 22479.00 17590.00 23635.00 Cylinder 6.00 6.00 4.00 4.00 4.00 4.00 Doors 4.00 2.00 2.00 2.00 2.00 2.00 Cruise 1.00 1.00 1.00 1.00 1.00 1.00 Sound 0.00 1.00 1.00 0.00 1.00 0.00 Leather 0.00 0.00 1.00 0.00 1.00 0.00 Buick 1.00 0.00 0.00 0.00 0.00 0.00 Cadillac 0.00 0.00 0.00 0.00 0.00 0.00 Chevy 0.00 1.00 0.00 0.00 0.00 0.00 Pontiac 0.00 0.00 0.00 0.00 0.00 0.00 Saab 0.00 0.00 1.00 1.00 1.00 1.00 Saturn 0.00 0.00 0.00 0.00 0.00 0.00 convertible 0.00 0.00 1.00 1.00 1.00 1.00 coupe 0.00 1.00 0.00 0.00 0.00 0.00 hatchback 0.00 0.00 0.00 0.00 0.00 0.00 sedan 1.00 0.00 0.00 0.00 0.00 0.00 wagon 0.00 0.00 0.00 0.00 0.00 0.00 > pairs.panels(cars) > > # lm > fit.lm <- glm(Price ~ ., data = cars) > summary(fit.lm) Call: glm(formula = Price ~ ., data = cars) Deviance Residuals: Min 1Q Median 3Q Max -9513.5 -1540.9 125.4 1470.3 13619.7 Coefficients: (3 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) -1.124e+03 9.926e+02 -1.133 0.25773 Mileage -1.842e-01 1.256e-02 -14.664 < 2e-16 *** Cylinder 3.659e+03 1.133e+02 32.286 < 2e-16 *** Doors 1.567e+03 2.589e+02 6.052 2.2e-09 *** Cruise 3.409e+02 2.960e+02 1.152 0.24978 Sound 4.409e+02 2.345e+02 1.880 0.06043 . Leather 7.908e+02 2.497e+02 3.167 0.00160 ** Buick 9.477e+02 5.525e+02 1.715 0.08670 . Cadillac 1.336e+04 6.248e+02 21.386 < 2e-16 *** Chevy -5.492e+02 4.397e+02 -1.249 0.21203 Pontiac -1.400e+03 4.868e+02 -2.875 0.00414 ** Saab 1.228e+04 5.546e+02 22.139 < 2e-16 *** Saturn NA NA NA NA convertible 1.102e+04 5.419e+02 20.340 < 2e-16 *** coupe NA NA NA NA hatchback -6.362e+03 6.104e+02 -10.422 < 2e-16 *** sedan -4.449e+03 4.463e+02 -9.969 < 2e-16 *** wagon NA NA NA NA --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for gaussian family taken to be 8445957) Null deviance: 7.8461e+10 on 803 degrees of freedom Residual deviance: 6.6639e+09 on 789 degrees of freedom AIC: 15122 Number of Fisher Scoring iterations: 2
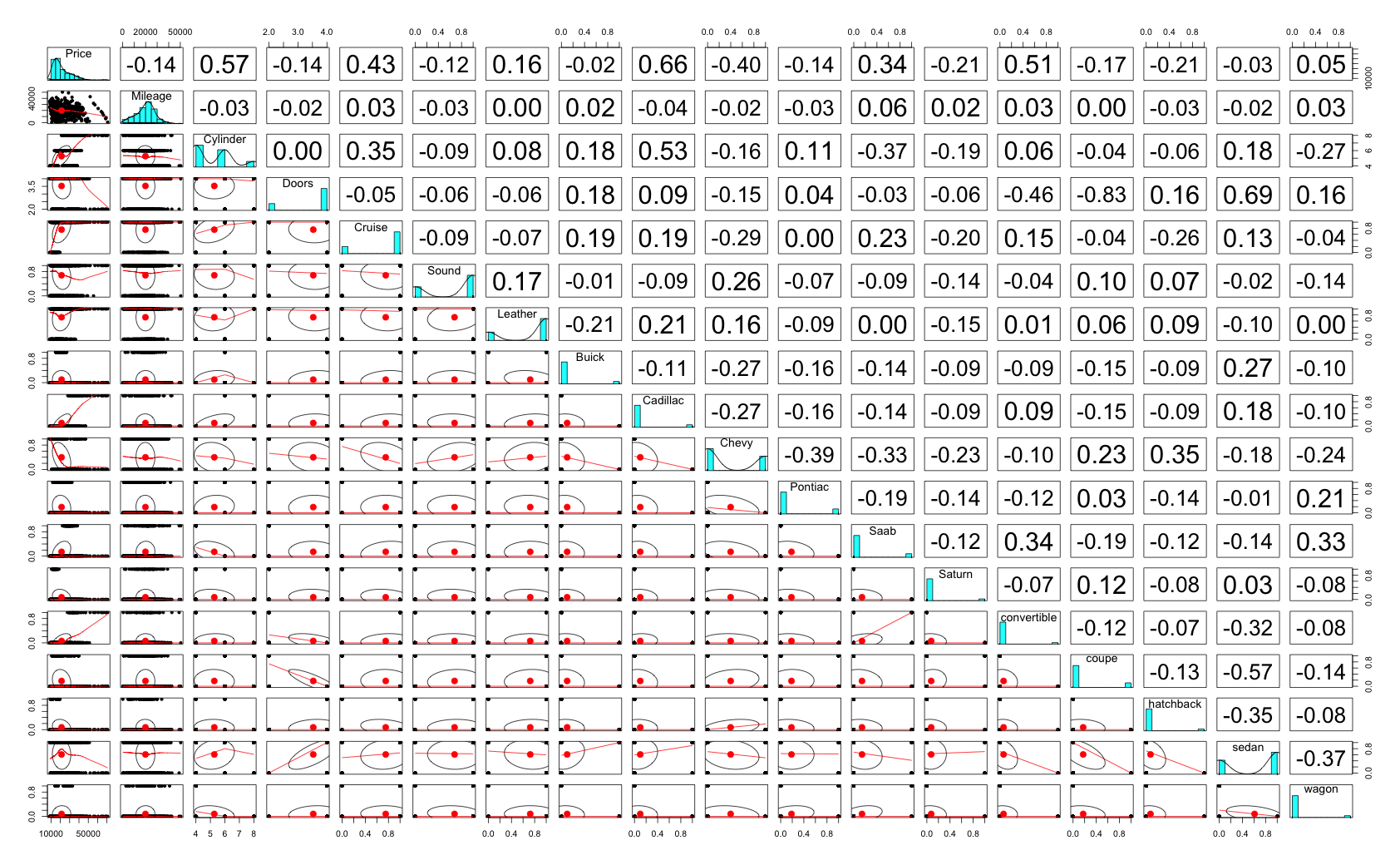
相関は各変数そこそこある感じで,極端に高いものはないみたいです.でもlm()の結果をみると,Saturnとcoupeとwagonは落ちちゃってますね.まぁその辺りは気にせず次へ.
glmnetでL1正則化
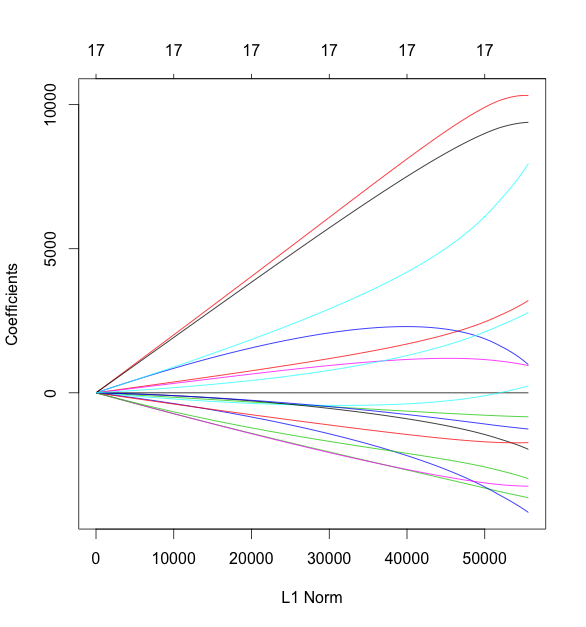
Rで正則化をするパッケージとして {glmnet} を使います.読み込みにfactor型は使えず,すべて数値型で渡す必要があります.かつYとXは別のmatrixとして渡してあげる必要があるとのこと.実行して,plotしてみます.式中の alpha が1ならL1正則化で,0ならL2正則化になります.そしてその間ならElastic Netです.
> pairs.panels(cars) > # lasso > fit.glmnet.lasso <- glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + alpha = 1) > plot(fit.glmnet.lasso)

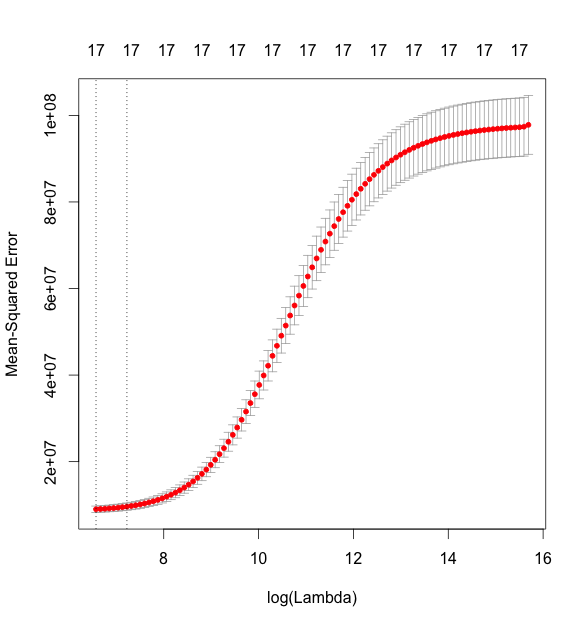
この図は,左にいくほどL1正則化が強く効いている状態とのことです.さらに cv.glmnet() で5 foldのクロスバリデーションを行います.
> fit.glmnet.lasso.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 1) > plot(fit.glmnet.lasso.cv) > fit.glmnet.lasso.cv$lambda.min [1] 18.54925 > fit.glmnet.lasso.cv$lambda.1se [1] 275.4505 > coef(fit.glmnet.lasso.cv, s = fit.glmnet.lasso.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 3332.5402054 Mileage -0.1816504 Cylinder 3634.6147087 Doors -628.9022241 Cruise 340.6710317 Sound 382.0774957 Leather 753.7844280 Buick 924.8954890 Cadillac 13401.5393074 Chevy -482.8713605 Pontiac -1294.4163546 Saab 12273.6389734 Saturn . convertible 11016.0739756 coupe . hatchback -1881.6575830 sedan . wagon 4317.2107830

MSE*3が最小になる lambda の値が18.55です.上の図において,log(lambda) = 3 あたりに点線が縦に引かれていますが,これがminの位置になります.で,真ん中ぐらいにある点線が,lambdaの1se地点の値です.lm() の結果と,lambda.minにおける各係数のあたいをみてみると,微妙に違いがありますね.lassoの場合はwagonではなくsedanが係数0に収束しているようです.
ちなみに,coef() を実行したときにオプションで指定している s というのは,coef を表示する際の lambda の値を指します. cranのドキュメントには,p18の predict.cv.glmnet に
Value(s) of the penalty parameter lambda at which predictions are required. Default
is the value s="lambda.1se" stored on the CV object. Alternatively
s="lambda.min" can be used. If s is numeric, it is taken as the value(s) of
lambda to be used.
と記述されています.
L2正則化
同じように,今度は alpha を0にして,ridge回帰をおこなってみます.
> # ridge > fit.glmnet.ridge <- glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + alpha = 0) > plot(fit.glmnet.ridge) > ## cv > fit.glmnet.ridge.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 0) > plot(fit.glmnet.ridge.cv) > fit.glmnet.ridge.cv$lambda.min [1] 714.8007 > fit.glmnet.ridge.cv$lambda.1se [1] 1370.924 > coef(fit.glmnet.ridge.cv, s = fit.glmnet.ridge.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 10337.0169783 Mileage -0.1712252 Cylinder 3170.1294044 Doors -831.5817913 Cruise 1026.4850774 Sound 224.6847147 Leather 956.7665236 Buick -1936.7129470 Cadillac 10320.3212670 Chevy -3629.5572140 Pontiac -4111.5436304 Saab 7869.4887792 Saturn -3239.5070500 convertible 9384.0693961 coupe -1729.7150676 hatchback -2962.1017215 sedan -1250.9639471 wagon 2760.2080200
lassoのときとは結果が大きく変わりました.
ElasticNetによる正則化
最後に,ElasticNetを試してみます.基本的には,0 < alpha < 1 であればよいのですが,この alpha の値を決める方法は,{glmnet} 内では提供されていません*4ので,今回はえいやで alpha=0.5 にしちゃいます.ちゃんとやりたいのであれば,{caret} あたりを使って,lambda とalpha を共に変動させてみるのがよいかと思います.
> fit.glmnet.elasticnet.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 0.5) > plot(fit.glmnet.elasticnet.cv) > fit.glmnet.elasticnet.cv$lambda.min [1] 33.80277 > fit.glmnet.elasticnet.cv$lambda.1se [1] 416.7364 > coef(fit.glmnet.elasticnet.cv, s = fit.glmnet.elasticnet.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 3864.0228103 Mileage -0.1815926 Cylinder 3625.4650658 Doors -626.2371069 Cruise 371.2344641 Sound 386.8548536 Leather 767.8711841 Buick 402.2514994 Cadillac 12865.1630823 Chevy -1013.4253903 Pontiac -1821.5463454 Saab 11707.2380808 Saturn -464.8502014 convertible 11028.5218995 coupe . hatchback -1877.0655854 sedan -3.3327249 wagon 4323.9610872
ということで,{glmnet} でL1/L2正則化を試してみました.なお,コードはgistにあげてあるので,興味がある方はどうぞ.
*1:単に「正則化 amazon」で検索したら一番上に出てきたのがビショップ本だっただけです.
*2:MiluHatsuneさんのエントリがわかりやすかったので,それをベースになぞってる感じです.
*3:Mean Squared Error,つまり予測値と実際の値の差の二乗和を意味します.
*4:cross validation - Choosing optimal alpha in elastic net logistic regression - Cross Validated
RStudio Serverの更新とロケール設定
RStudio Serverを久しぶりに使おうと思ってアクセスしたら,なんかバージョンが古すぎてggplot2もdplyrもtidyrも入れられない有様だったので,アップデートをしましたよの備忘録.元バージョンはR3.1.0にRStudio0.97あたり.OSはCentOS6.5でした.
Rについては,cranから最新版を落としてmakeしてinstallすればOK.コンパイルの際には enable-R-shlib をつけないとダメとのこと*1.ちなみにyumから入れると3.1.0だったので,基本的にソースからビルドせざるをえない感じです.
$ cd /tmp $ wget wget https://cran.r-project.org/src/base/R-3/R-3.2.3.tar.gz $ tar xvf R-3.2.3.tar.gz $ cd R-3.2.3 $ ./configure --with-readline=no --with-x=no --enable-R-shlib $ make $ sudo make install
続いてRStudio Serverのインストール.こっちはrpmを公式から落としてきて,yumで入れればOK.
$ wget https://download2.rstudio.org/rstudio-server-rhel-0.99.879-x86_64.rpm $ sudo yum install --nogpgcheck rstudio-server-rhel-0.99.879-x86_64.rpm
で,このあと `sudo rstudio-server restart` したら,なんか以下のようなエラーがでてうまく動いてくれない.localeコマンドでわかる通り,これはOSのロケールが適切に設定されていないときに出るエラーとのこと.
$ sudo rstudio-server restart 16 Feb 2016 07:25:10 [rserver] ERROR Unexpected exception: locale::facet::_S_create_c_locale name not valid; LOGGED FROM: int main(int, char* const*) /root/rstudio/src/cpp/server/ServerMain.cpp:547 /usr/sbin/rstudio-server: line 33: return: can only `return' from a function or sourced script rstudio-server start/running, process 4032 $ locale locale: Cannot set LC_CTYPE to default locale: No such file or directory locale: LC_ALL?????????????????????: ?????????????????????? ...
この場合,LC_CTYPEを設定してあげて,再起動すればOK.このあたりの変数の意味は,このあたりを参照してください.
$ sudo vim /etc/sysconfig/i18n LANG="en_US.UTF-8" LC_CTYPE="ja_JP.UTF-8" # この行を追加 SYSFONT="latarcyrheb-sun16" $ sudo reboot
これで無事アクセスできました.
*1:shlibっていうのはshared libraryのことらしいです
データビジネスに関して2015年に読んだ本
気がつけば2015年も大晦日で,早い一年でした.ということで,恒例の今年読んだ本紹介をしておきたいと思います.ちなみに昨年と一昨年のはこちら.各セグメント毎に,個人的に参考になった順,面白かった順に並べています.マーケティングとマネジメントが前面に出ているのが,普段のお仕事で担当しているのがそっちメインだから,というだけで他意はないです.
smrmkt.hatenablog.jp
smrmkt.hatenablog.jp
マーケティング
USJのジェットコースターはなぜ後ろ向きに走ったのか?

- 作者: 森岡毅
- 出版社/メーカー: KADOKAWA/角川書店
- 発売日: 2014/02/26
- メディア: 単行本
- この商品を含むブログ (3件) を見る
こころを動かすマーケティング

こころを動かすマーケティング―コカ・コーラのブランド価値はこうしてつくられる
- 作者: 魚谷雅彦
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2009/08/07
- メディア: 単行本
- 購入: 4人 クリック: 41回
- この商品を含むブログ (23件) を見る
売れるもマーケ 当たるもマーケ

- 作者: アルライズ,ジャックトラウト,Al Ries,Jack Trout,新井喜美夫
- 出版社/メーカー: 東急エージェンシー出版部
- 発売日: 1994/01
- メディア: 単行本
- 購入: 17人 クリック: 250回
- この商品を含むブログ (61件) を見る
ラストワンマイル

- 作者: 楡周平
- 出版社/メーカー: 新潮社
- 発売日: 2006/10/26
- メディア: 単行本
- クリック: 4回
- この商品を含むブログ (15件) を見る
スマホに満足してますか
")
スマホに満足してますか? ユーザインタフェースの心理学 (光文社新書)
- 作者: 増井俊之
- 出版社/メーカー: 光文社
- 発売日: 2015/02/17
- メディア: 新書
- この商品を含むブログ (8件) を見る
マネジメント
ピクサー流 創造するちから

ピクサー流 創造するちから―小さな可能性から、大きな価値を生み出す方法
- 作者: エド・キャットムル著,エイミー・ワラス著,石原薫訳
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2014/10/03
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (9件) を見る
ワークルールズ

- 作者: ラズロ・ボック,鬼澤 忍,矢羽野 薫
- 出版社/メーカー: 東洋経済新報社
- 発売日: 2015/07/31
- メディア: 単行本
- この商品を含むブログ (5件) を見る
巨像も踊る

- 作者: ルイス・V・ガースナー,山岡洋一,高遠裕子
- 出版社/メーカー: 日本経済新聞社
- 発売日: 2002/12/02
- メディア: 単行本
- 購入: 22人 クリック: 313回
- この商品を含むブログ (94件) を見る
経営パワーの危機
")
経営パワーの危機―会社再建の企業変革ドラマ (日経ビジネス人文庫)
- 作者: 三枝匡
- 出版社/メーカー: 日本経済新聞社
- 発売日: 2003/03
- メディア: 文庫
- 購入: 21人 クリック: 99回
- この商品を含むブログ (51件) を見る
リスク確率に基づくプロジェクト・マネジメントの研究

リスク確率に基づくプロジェクト・マネジメントの研究【知の偉産シリーズ】 理工00005
- 作者: 佐藤知一
- 出版社/メーカー: 静岡学術出版
- 発売日: 2013/02/01
- メディア: DVD-ROM
- この商品を含むブログを見る
brevis.exblog.jp
統計学・機械学習
オンライン機械学習
")
- 作者: 海野裕也,岡野原大輔,得居誠也,徳永拓之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
smrmkt.hatenablog.jp
smrmkt.hatenablog.jp
深層学習
")
- 作者: 岡谷貴之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (6件) を見る
基礎からのベイズ統計学

基礎からのベイズ統計学: ハミルトニアンモンテカルロ法による実践的入門
- 作者: 豊田秀樹
- 出版社/メーカー: 朝倉書店
- 発売日: 2015/06/25
- メディア: 単行本
- この商品を含むブログ (4件) を見る
岩波データサイエンス

- 作者: 岩波データサイエンス刊行委員会
- 出版社/メーカー: 岩波書店
- 発売日: 2015/10/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (6件) を見る
データ分析プロセス
")
- 作者: 福島真太朗,金明哲
- 出版社/メーカー: 共立出版
- 発売日: 2015/06/25
- メディア: 単行本
- この商品を含むブログ (2件) を見る
組み合わせ最適化とアルゴリズム
")
組合せ最適化とアルゴリズム (インターネット時代の数学シリーズ 8)
- 作者: 久保幹雄,戸川隼人,杉原厚吉,中嶋正之,野寺隆志
- 出版社/メーカー: 共立出版
- 発売日: 2000/12/10
- メディア: 単行本
- 購入: 3人 クリック: 57回
- この商品を含むブログ (7件) を見る
集合知プログラミング

- 作者: Toby Segaran,當山仁健,鴨澤眞夫
- 出版社/メーカー: オライリージャパン
- 発売日: 2008/07/25
- メディア: 大型本
- 購入: 91人 クリック: 2,220回
- この商品を含むブログ (276件) を見る
ベイズ統計と統計物理

- 作者: 伊庭幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2003/08/27
- メディア: 単行本
- 購入: 13人 クリック: 151回
- この商品を含むブログ (41件) を見る
はじめてのパターン認識

- 作者: 平井有三
- 出版社/メーカー: 森北出版
- 発売日: 2012/07/31
- メディア: 単行本(ソフトカバー)
- 購入: 1人 クリック: 7回
- この商品を含むブログ (3件) を見る
入門オペレーションズリサーチ

- 作者: 松井泰子,根本俊男,宇野 毅明
- 出版社/メーカー: 東海大学出版会
- 発売日: 2008/03
- メディア: 単行本
- 購入: 1人 クリック: 56回
- この商品を含むブログ (4件) を見る
エンジニアリング
コンピュータ・アーキテクチャ技術入門
")
コンピュータアーキテクチャ技術入門 ~高速化の追求×消費電力の壁 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2014/05/01
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
")
プロセッサを支える技術 ??果てしなくスピードを追求する世界 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2011/01/06
- メディア: 単行本(ソフトカバー)
- 購入: 22人 クリック: 250回
- この商品を含むブログ (54件) を見る
計算機に関わるハードウェア全般の概説書.何年か前に,同じHisa Andoさんのプロセッサを支える技術を読みましたけど,これのさらに拡張版といった趣きの本.富豪的プログラミングができる場合も多々ある現在では,コードを書く際に実行環境の方には割と無頓着でもそんなに問題はないのですが,場合によってはかなり気を使わないといけないことも結構あります.特にAPIのレイテンシを気にしないといけない場合とか,大規模行列演算をやるとか,Hadoop使うとかみたいな場合には,ソフトウェア実装の前提なるハードウェア構成を考えていないとうまく機能しないです.そのあたりを(結構記述は込み入っていて理解するのは時間がかかりますが,それでも他に類書がないくらいに)わかりやすく説明している,とても良い本だと思います.
理論から学ぶ実践データベース入門
")
理論から学ぶデータベース実践入門 ~リレーショナルモデルによる効率的なSQL (WEB+DB PRESS plus)
- 作者: 奥野幹也
- 出版社/メーカー: 技術評論社
- 発売日: 2015/03/10
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (13件) を見る
SQL実践入門
")
SQL実践入門──高速でわかりやすいクエリの書き方 (WEB+DB PRESS plus)
- 作者: ミック
- 出版社/メーカー: 技術評論社
- 発売日: 2015/04/11
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
データ匿名化手法

- 作者: Khaled El Emam,Luk Arbuckle,木村映善,魔狸,笹井崇司
- 出版社/メーカー: オライリージャパン
- 発売日: 2015/05/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
熊とワルツを

- 作者: トム・デマルコ,ティモシー・リスター,伊豆原弓
- 出版社/メーカー: 日経BP社
- 発売日: 2003/12/23
- メディア: 単行本
- 購入: 7人 クリック: 110回
- この商品を含むブログ (150件) を見る
プログラミングHive

- 作者: Edward Capriolo,Dean Wampler,Jason Rutherglen,佐藤直生,嶋内翔,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/06/15
- メディア: 大型本
- この商品を含むブログ (3件) を見る
初めてのSpark

- 作者: Holden Karau,Andy Konwinski,Patrick Wendell,Matei Zaharia,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2015/08/22
- メディア: 大型本
- この商品を含むブログ (3件) を見る
HBase徹底入門

HBase徹底入門 Hadoopクラスタによる高速データベースの実現
- 作者: 株式会社サイバーエージェント鈴木俊裕,梅田永介,柿島大貴
- 出版社/メーカー: 翔泳社
- 発売日: 2015/01/28
- メディア: 大型本
- この商品を含むブログ (1件) を見る
smrmkt.hatenablog.jp
サーバ/インフラエンジニア養成読本 管理/監視編
![【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)](http://ecx.images-amazon.com/images/I/51UVepGMSfL._SL160_.jpg "【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)")
【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)
- 作者: 養成読本編集部
- 出版社/メーカー: 技術評論社
- 発売日: 2014/04/11
- メディア: 大型本
- この商品を含むブログ (3件) を見る
Webエンジニアが知っておきたいインフラの基本

- 作者: 馬場俊彰(ハートビーツ)
- 出版社/メーカー: マイナビ出版
- 発売日: 2014/12/27
- メディア: Kindle版
- この商品を含むブログを見る
システムはなぜダウンするのか

- 作者: 大和田尚孝,日経コンピュータ
- 出版社/メーカー: 日経BP社
- 発売日: 2009/01/22
- メディア: 単行本
- 購入: 24人 クリック: 345回
- この商品を含むブログ (45件) を見る
IT投資の評価手法

- 作者: 大和田崇
- 出版社/メーカー: 中央経済社
- 発売日: 2007/03
- メディア: 単行本
- 購入: 1人 クリック: 8回
- この商品を含むブログ (4件) を見る
徹底解説! プロジェクトマネジメント

- 作者: 岡村正司
- 出版社/メーカー: 日経BP社
- 発売日: 2003/06/28
- メディア: 単行本
- 購入: 1人 クリック: 6回
- この商品を含むブログ (6件) を見る
その他
トップレフト

- 作者: 黒木亮
- 出版社/メーカー: サウンズグッド カンパニー
- 発売日: 2014/04/25
- メディア: Kindle版
- この商品を含むブログを見る
要するに
")
- 作者: 山形浩生
- 出版社/メーカー: 河出書房新社
- 発売日: 2008/02/04
- メディア: 文庫
- 購入: 9人 クリック: 145回
- この商品を含むブログ (57件) を見る
HiveでISO8601形式の時刻データを扱う
連日イカに潜っているため,すっかりご無沙汰になっている当ブログです.今回は小ネタ.
HDFS上に保存しているデータの日付カラムがISO8601形式だったりすることがよくあるんですけど,これってHiveのtimestamp型で読み込めないんですね.蜂初心者なので全く知りませんでした.なのでテーブルスキーマだとstringで扱うしかないのが辛いところ.とはいえクエリの段ではtimestampに変換したいですね,というのが今回のお話,
ちなみにISO8601ってこういうやつですね.Tとタイムゾーンが入ってるのが特徴.
2015-01-02T12:34:56+09:00
どうやら組み込み関数ではISO8601は取り扱いできないので,UDF使えばいけそうであると.このサイトにあるように,以下のような形でさくっと変換できます*1.
ADD JAR hdfs:///external-jars/commons-codec-1.9.jar; ADD JAR hdfs:///external-jars/joda-time-2.2.jar; ADD JAR hdfs:///external-jars/sm-hive-udf-1.0-SNAPSHOT.jar; SELECT from_unixtime(iso8601_to_unix_timestamp(target_date), 'yyyy-MM-dd-HH-mm-ss') FROM test_table;
でもUDF読むのも面倒だったので,組み込み関数組み合わせてこんな感じで凌ぐと.Hiveには正規表現使わないreplace関数はないんですね.まぁMapReduce噛ませるんだから,普通のreplaceでも正規表現使ったreplaceでも大差ないじゃんってことなのかなぁと想像*2.
SELECT CAST(regexp_replace(substr(target_date, 0, 19), 'T', ' ') AS timestamp) AS target_date FROM test_table;
そんだけです.
勾配ブースティングについてざっくりと説明する
最近xgboostがだいぶ流行っているわけですけど,これはGradient Boosting(勾配ブースティング)の高速なC++実装です.従来使われてたgbtより10倍高速らしいです.そんなxgboostを使うにあたって,はてどういう理屈で動いているものだろうと思っていろいろ文献を読んだのですが,日本語はおろか,英語文献でもそんなに資料がなかったので,ある程度概要を把握するのに結構時間を食いました.
そんなわけで,今回は自分の理解の確認も兼ねて,勾配ブースティングについてざっくりと説明してみようかと思います.とはいえ生理解な部分も結構あるので,マサカリが飛んできそう感が大いにしています.腑に落ちる的な理解を優先しているため,数式は一切出てきません.
勾配ブースティングとは
複数の弱学習器を組み合わせるアンサンブル学習には,いくつかの手法がありますが,ブースティングは逐次的に弱学習器を構築していく手法です.逐次的というのは,弱学習器を1つずつ順番に構築していくという意味です.新しい弱学習器を構築する際に,それまでに構築されたすべての弱学習器の結果を利用します.そのためすべての弱学習器が独立に学習されるバギングと比べると,計算を並列化できず学習に時間がかかります.
ブースティングでは,各ステップごとに弱学習器を構築して損失関数を最小化します.その際に,各学習データの扱いはずっと平等ではありません.各学習データのうち,前のステップで間違って識別されたものへのウェイトを重くして,次のステップで間違ったものをうまく識別できるようにしていきます.
各ステップ内でやることは,ようするに損失関数の最小化問題です.これだけ切り出せば,通常の最適化問題とそれほど大きくは変わりません.最適化問題でよく使われる最急降下法やニュートン法なんかをまとめて,勾配降下法ということができます.勾配ブースティングでやっていることは,各ステップのパラメタ最適化の際に,勾配降下法を用いているというだけのことです.もちろん数学的にはいろいろあるわけですけれども,大枠としてはそれだけです.勾配を求めて学習していく,という形をとるので,損失関数をパラメタ行列で微分してあげるのを繰り返して,所定回数に達したらおしまいです.
このあたり,数式的にしっかり追いたいというのであれば,はじパタの11.4や,統計的学習の基礎の10.10,Introduction to Boosted TreesやFEGさんのKDD Cupまとめあたりを参照してください.
- 作者: 平井有三
- 出版社/メーカー: 森北出版
- 発売日: 2012/07/31
- メディア: 単行本(ソフトカバー)
- 購入: 1人 クリック: 7回
- この商品を含むブログ (3件) を見る

- 作者: Trevor Hastie,Robert Tibshirani,Jerome Friedman,杉山将,井手剛,神嶌敏弘,栗田多喜夫,前田英作,井尻善久,岩田具治,金森敬文,兼村厚範,烏山昌幸,河原吉伸,木村昭悟,小西嘉典,酒井智弥,鈴木大慈,竹内一郎,玉木徹,出口大輔,冨岡亮太,波部斉,前田新一,持橋大地,山田誠
- 出版社/メーカー: 共立出版
- 発売日: 2014/06/25
- メディア: 単行本
- この商品を含むブログ (3件) を見る
勾配ブースティングのパラメタ
勾配ブースティングでよく使われるのは,弱識別器に決定木をもちいたGBDT(Gradient Boosting Decision Tree)です.xgboostなんかでも,こちらにパラメタ一覧がまとまっています.GBDTの場合,過学習の制御がパラメタ決定の中心になってきます.
例えば各ステップの学習が後続ステップの学習に影響を及ぼしてしまうため,個々のステップの影響を下げて学習速度をゆっくりにするshrinkageと呼ばれるパラメタがあります.shrinkageのパラメタは
の値を取ります(xgboostだと,このパラメタはetaで表され,デフォルトは0.3になっています).ある程度小さいほうが,過学習が抑制されて精度が上がります.過学習に関しては,深層学習によくまとまっています.というのは,ニューラルネットワークは非常に表現力が高い手法であるため,過学習に陥りやすいという特性があります.そこで,いかにして過学習を防ぎながら多層ニューラルの最適値を得るかについて,様々な研究の蓄積があります.
- 作者: 岡谷貴之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
また個々の弱学習器である,決定木自体の表現力を制御するパラメタとして,木の深さ(xgboostだとmax_depth)や葉の重みの下限(同じくmin_child_weight),葉の追加による損失減少の下限(gamma)といったものがあります.深さが浅いほど,また下限が大きいほど,当然単純な木になりやすいので過学習の抑制に働きます.
あとは各ステップで決定木の構築に用いるデータの割合というパラメタもあります.学習データから非復元抽出したサブサンプルを用いることで,確率的勾配降下法(Stochastic Gradient Descent: SGD)に近い効果が得られると思われます.当然これも過学習抑制で精度向上につながります.SGDについては最近出版されたオンライン機械学習でも詳しく述べられていて,理解の助けになるかと思います.
- 作者: 海野裕也,岡野原大輔,得居誠也,徳永拓之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
またxgboostにはcolsample_bytreeというパラメタもあり,これは各ステップの決定木ごとに用いる特徴量をサンプリングすることだと思われます.これはランダムフォレストで行われているのと同じで*1,特徴量同士の交互作用を考慮した形のモデリングができるという利点があります.
それ以外にも,木の本数(nrounds)もあります.当然木の本数が多いほうが結果も安定するし精度も上がりますが,その一方で学習に時間がかかってしまいます.先ほども述べたように,ブースティングはパラメタの推定時に前のステップの結果を用いるため,各ステップの推定を同時に行うことができません.そのためステップ数が増えること(=木の本数が増えること)は,計算時間の増加を招きます.
xgboostパッケージを試してみる
ということで,ようやくですがxgboostを使っていくつかパラメタのシミュレーションをしてみます.データはStackingのときにも使ったバイナリデータです.各パラメタを何段階かで変えてみて,予測率の変化をみてみましょう.
値を変えてみたパラメタ以外のものについては,基本的にデフォルトの値に固定しています.パラメタのデフォルト一覧は以下の通りです*2.
| パラメタ | 値 |
|---|---|
| nrounds | 100*3 |
| eta | 0.3 |
| gamma | 0 |
| max.depth*4 | 6 |
| min.child.weight | 1 |
| subsumple | 1 |
| colsumple.bytree | 1 |
ということで,以下に各パラメタの値を動かしたときに,どの程度正解率が変化するかをまとめてみました.そんなに極端に動くわけではありませんね.
nrounds
| nrounds | accuracy |
|---|---|
| 1 | 82.9% |
| 10 | 85.1% |
| 100 | 84.8% |
| 1000 | 83.1% |
gamma
| gamma | accuracy |
|---|---|
| 0 | 84.8% |
| 0.1 | 84.8% |
| 0.3 | 85.4% |
| 0.5 | 85.3% |
max.depth
| max.depth | accuracy |
|---|---|
| 3 | 85.3% |
| 6 | 84.8% |
| 10 | 85.3% |
| 20 | 84.5% |
min.child.weight
| min.child.weight | accuracy |
|---|---|
| 0.1 | 84.6% |
| 1 | 84.8% |
| 3 | 85.2% |
| 10 | 85.4% |
subsumple, colsumple.bytree
なぜかこれらについては,パラメタを変えても実際のモデルに変化がなく,何故なのかがよくわからず...
コードは例のごとくgistにあげているので,ご参考までに.
Optimizelyのstats engineによる逐次A/Bテスト
ABテストといえば,だいぶ前に有意とか検定とかそのあたりで,データ系の界隈がいろいろと盛り上がっていたのが記憶に残っているトピックなわけですが,今年の1月にABテストの大手Optimizelyのエンジンがリニューアルされてました.これがなかなか興味深いんで,今回はざっくりとその内容をご紹介します*1.
とりあえず元ネタは以下の記事とテクニカルペーパーになります.
http://pages.optimizely.com/rs/optimizely/images/stats_engine_technical_paper.pdf
以下の内容は,基本的にはそこに書かれている内容の要約になります.
従来のABテストの問題点
これまでの,いわゆる古典的な統計学に従ったABテストの場合,以下のような問題があります.
- 想定される差分やサンプルサイズについて,事前に見積もっておかないといけない
- あらかじめ決めたサンプルサイズに達する前に何度も結果を覗くことで,間違った結果を得てしまうことがある
- たくさんのバリエーションを一度にテストすることで,誤検出率が上がってしまう
サンプルサイズの事前見積もり
ABテストというのは,ようするに比率の差の検定なわけですけれども,実験的にこれを実施するためのお作法として,事前に想定効果を見積もって,それを検出可能なサンプルサイズを決定します.その上で得られたデータに対して,実際に差が出たかどうかを検定します.これは有名なスチューデントのt検定が,ビールの麦芽汁に酵母液をどれくらい入れればよいのかを決定するための手段として生み出されたように,生産現場において条件を変えて実験する,みたいなものにはとてもよく当てはまります.
しかしながら,Webの世界のABテストのように,サンプルは時間とともにどんどん入ってくるような環境だと,逆に足かせになります.穀物生産の現場ならいざ知らず,WebのUIテストのようなもので,事前に想定効果を事前に見積もるのは至難の技です.もちろんベースラインのパターンのコンバージョン率については,あらかじめログ集計でもしておけばいいわけですけれども,新しいパターンのデザインで3%あがるか,5%あがるかなんてよくわかりませんよね.
結果を何度もみることの影響
そしてABテストツールがあって,時間とともにサンプルが増えてコンバージョン率の折れ線グラフが更新されるというのに,事前に決めたサンプルサイズが溜まるまでそれを見ない,というのも現実的ではないわけです.コンバージョン率には揺らぎがあるため,実験期間中の短い間に5%有意ラインを超えることもよくあります.このときたまたま結果を眺めてたとしたら,差が出たと思って実験を早期に打ち切っちゃう(=偽陽性の結果となるわけです)なんてパターンがかなりあります.
以下の図は,Optimizelyの記事上にある画像を持ってきたものですが,ベースラインに対して新しい実験パターンのコンバージョンの方がずっと優勢なんですが,95%ラインを越えたり越えなかったり,という推移が見て取れます.ごく初期に95%を越えた段階で効果あり,と思って実験をストップしちゃうなんていうのは割とありがちな事態ではないでしょうか.

ソリューション
上記の問題を解決するために,彼らは以下の2つの枠組みを用いた新しいテストエンジンを作ったそうです.
逐次検定ベースのテスト
これまで,古典的統計学の枠組みにそった検定を行っていたことによる問題を,逐次検定を用いることで回避しました.逐次検定は,サンプルが追加されるごとに尤度比を計算して,その尤度比が想定していた閾値を超えた時点で有意とみなす,という手法になります.
実験群と統制群の比率の差分は,the law of the iterated logarithmに従って減衰するということらしく,それをモデルに取り入れた形でスコアを定義しました.数式書くの面倒なので,テクニカルペーパーのp7にある(2)式を参照してください.これにより,時間経過に伴う差分の変動を考慮した形で,第1種の過誤を一定に保ったまま繰り返し検定を行えるようにしました.
偽陽性率ではなく偽発見率
上で説明したように,複数パターンでの同時テストは,偽陽性率の上昇という大きな問題を抱えています.これを解決するために,彼らは検定全体で偽陽性が発見される確率=偽発見率を定義し,ベイズの枠組みを用いて信頼区間を定める形をとりました.信頼区間の上限は,以下のような式で定義されます.を実験群と統制群の差分,
を
,
を帰無仮説が真である事前確率,
はABテストが行われた回数,
はサンプル数です.
すごくざっくりいうと,上の式で定義されるような,従来の偽陽性率よりも厳しい偽発見率という基準を用いることによって,第1種の過誤を減らす形の方策をとりました.これらの方略によって,従来数十%程度あった第1種の過誤が,一桁%にまで減少したそうです.
そんなわけで,すごいざっくりとしたOptimizelyのstats engineの紹介でした.このあたりの資料をいろいろみた挙句,そこまで頑張るならバンディッドでいいんじゃない? っていう感想が出てきたことはここだけの話です.
*1:細かい数式まわり,私自身もきちっと理解し切れているわけではないので,そこら辺解説してくれる人がいたら嬉しかったりします.