「熊とワルツを」のリスクシミュレーションをRで実装した
最近「熊とワルツを」というプロジェクトにおけるリスク管理についての本を読みました.本の中にでてくるリスク管理シミュレーションをR実装しました,という話です.

- 作者: トム・デマルコ,ティモシー・リスター,伊豆原弓
- 出版社/メーカー: 日経BP社
- 発売日: 2003/12/23
- メディア: 単行本
- 購入: 7人 クリック: 110回
- この商品を含むブログ (150件) を見る
ネタ元のトム・デマルコさんの本は,軽妙な語り口でとても読みやすいので,プロジェクトベースでお仕事する人はみんな一度は目を通してみるといいんじゃないかなと思います*1.偉い人の思いつきで,ケツの決まったプロジェクトを押し付けられそうになったときに,そんなんじゃ崩壊するだろって言い返すためにも*2.そんなわけで,シミュレーションの説明をする前段として,本の中で述べられているリスクについて軽く触れておきます.
5つのコアリスク
この本ではリスク管理について様々な観点から述べられているのですが,その中で主なリスク要素として以下の5つが挙げられています.
- スケジュールの欠陥
- 要求の増大
- 人員の離脱
- 仕様の崩壊
- 生産性の低迷
これらのリスク要因の中でも,4番目に挙げられた「仕様の崩壊」については,これが起こるとプロジェクト自体が崩壊して失敗するものとされています.それ以外の4つについては,発生によってスケジュール自体が5%〜20%のような幅のある見積もりで遅延するものと考えられます.
ツールの概要
ツールの中で実際に行われているのは,スケジュール遅延予測分布に基づいた,モンテカルロシミュレーションです.平たくいうと,スケジュールを実施する人が,いくつかのリスク要素についてあらかじめスケジュール遅延度合いを以下の3点で見積もります.
- スケジュールの最小遅延割合
- スケジュールの最頻遅延割合
- スケジュールの最大遅延割合
これを5つのコアリスクについて見積もります.ただし4番目の「仕様の崩壊」については,これが生じるとプロジェクト自体が失敗してしまうクリティカルなリスクということで,別途以下のように見積もります.
- 仕様崩壊が発生する確率
- 仕様崩壊が生じたときに,プロジェクトが失敗するか否か
- プロジェクトが失敗しない際に遅延する月数
- プロジェクトが失敗しない際に遅延する割合
シミュレーションでは,プロジェクトが失敗しないパターンも見積もることが可能で,その場合は遅延月数もしくは遅延割合のどちらかで,スケジュール遅延を表します.この数字は一般にとても大きくなるものと考えられます.
上記の値を設定した上で,乱数を用いて遅延度合いのサンプルを取得し,実際にどのくらいスケジュールが遅延するか(もしくは失敗するか)を計算します.これを繰り返し実施して,スケジュール遅延度合いの分布を作成します.これによってだいたいスケジュールがどのくらい遅延するかの目安を得ることができます.
Rでの実装
ということでコードをみていきます.フルバージョンはgithubリポジトリを参照してください.コードは設定ファイルと実行ファイルの2つに分かれています.設定ファイルは以下のようになります.
# trial iteration count N_TRIAL = 3000 # project period START_DATE = as.Date("2015/1/1") END_DATE = as.Date("2016/9/30") SPAN = END_DATE-START_DATE # fatal risk: SPECFLAW(failure to reach consensus) FR = list("prob"=0.15, "fatal"=TRUE, "month"=8, "rate"=0) # other risk factors RF = list(1:10, list()) ## RF01: SCHEDFLAW(error in original sizing) RF[[1]] = list("min"=0.0, "mode"=0.2, "max"=0.5) ## RF02: TURNOVER(effet of employee turnover) RF[[2]] = list("min"=0.0, "mode"=0.05, "max"=0.1) ## RF03: INFLATION(requirement function growth) RF[[3]] = list("min"=0.0, "mode"=0.1, "max"=0.2) ## RF04: PRODUCTIVITY(effect of productivity variance) RF[[4]] = list("min"=0.0, "mode"=0.05, "max"=0.2) ## RF05: OTHER RISK RF[[5]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF06: OTHER RISK RF[[6]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF07: OTHER RISK RF[[7]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF08: OTHER RISK RF[[8]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF09: OTHER RISK RF[[9]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF10: OTHER RISK RF[[10]] = list("min"=0.0, "mode"=0.0, "max"=0.0)
4番目の「仕様の崩壊」については,別計算が必要なので"fatal risk"として別途切り出しています.項目は順にリスクの発生確率,発生時にプロジェクトが崩壊するか否か,崩壊しない場合の遅延月数,遅延割合です.「仕様崩壊」がないとする場合には,prob=0としてください.それ以外の4つ+予備の5つのリスク要素について,最小値,最頻値,最大値を割合で入力します.その要素の影響が特にない場合には,3つとも0に設定してください.
それ以外に,プロジェクトの開始日時と終了日時を設定可能です.実際のプロジェクト開始日と終了日を適宜変更して入れてください.またシミュレーションの実行回数は,とりあえず3000回としてありますが,任意に変更可能です*4.本体のriskology.Rを実行すると,結果として以下のように結果が得られます.また "img/histgram_of_delays.png" にヒストグラムが画像で保存されます.ヒストグラムを見るとわかるように,今回の設定だとプロジェクトは最低100日以上,平均して250日程度遅延することがみてとれます.
> sprintf("iteration count: %d", N_TRIAL) [1] "iteration count: 3000" > sprintf("project cancel count with fatal risk: %d", cancelled) [1] "project cancel count with fatal risk: 463" > sprintf("cancel rate: %02.1f%%", cancelled/N_TRIAL*100) [1] "cancel rate: 15.4%" > print("Summary of delay days:") [1] "Summary of delay days:" > summary(delays) Min. 1st Qu. Median Mean 3rd Qu. Max. 108.0 217.0 253.0 254.2 291.0 426.0 >
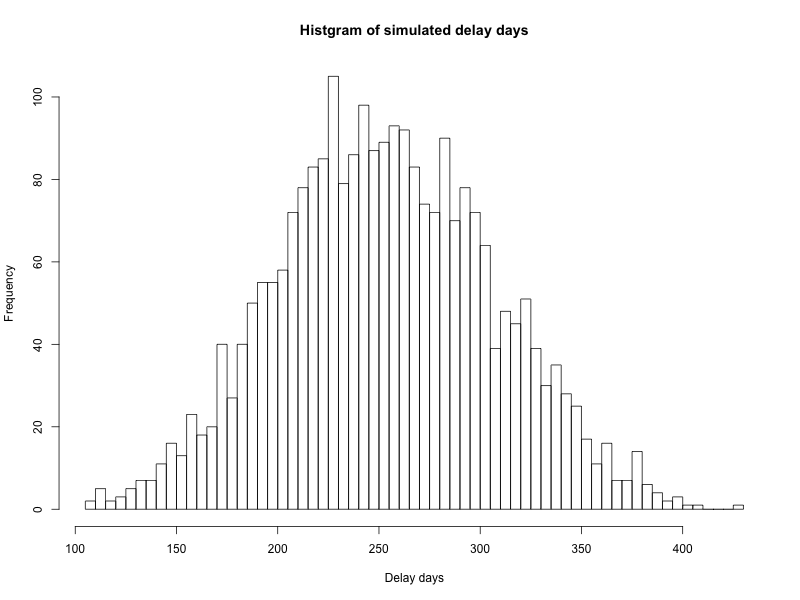
そんなわけで,ちゃんとスケジュール遅延の可能性を分布で把握して,炎上しないように楽しくプロジェクトをこなしていきましょう*5.
最後にそしてシミュレーション本体はこちらです.
source("conf.R") # risk distribution sampler sampler = function(rf_, total=10) { range = rf_[["max"]]-rf_[["min"]] alpha = total*(rf_[["mode"]]-rf_[["min"]])/range beta = total*(rf_[["max"]]-rf_[["mode"]])/range sample = rbeta(1, alpha, beta) sample*range } # calculate fatal risk fatal_risk = function(fr) { if (fr[["prob"]] < runif(1)) { return(0) } else { if (fr[["fatal"]]) { return(-1) } else { month = fr[["month"]]*30 rate = (END_DATE-START_DATE)*fr[["rate"]] return(max(month, rate)) } } } # calculate delay factor delay_factor = function(RF) { df = 0 for (i in 1:length(RF)) { df = df+sampler(RF[[i]]) } df } # calcurate delay cancelled = 0 delays = c() for (i in 1:N_TRIAL) { delay = 0 # check fatal risk fatal = fatal_risk(FR) if (fatal == -1) { cancelled = cancelled+1 next } else { delay = delay+fatal } # add other risk factors for (i in 1:length(RF)) { delay = delay+(END_DATE-START_DATE)*sampler(RF[[i]]) } delays = c(delays, as.integer(delay)) } # draw histgram png("img/histgram_of_delays.png", width=800, height=600) hist(delays, breaks=max(10, as.integer(N_TRIAL/30)), main="Histgram of simulated delay days", xlab="Delay days", ylab="Frequency") dev.off() # print result sprintf("iteration count: %d", N_TRIAL) sprintf("project cancel count with fatal risk: %d", cancelled) sprintf("cancel rate: %02.1f%%", cancelled/N_TRIAL*100) print("Summary of delay days:") summary(delays)
dplyrを使ったdata.frameの前処理を関数化する
表題の通り,dplyr使って前処理する際に,それを関数化する方法のメモ.ユースケースとしては,ちょっとだけ条件変えてデータフレーム自体を何度か出し直すってとき用.
関数
まるっとフィルタ用のconditionと,select用のvariablesを引数で渡します*1.ポイントは,filterではなくfilter_とアンスコが付いていること.これは,この処理がNon-Standard Evaluation*2で評価してはいけないからです.
preprocess = function(df, condition, variables) { df %>% filter_(condition) %>% select_(variables) }
呼び出し側
呼び出し側は,条件文をquote()に入れて渡します.selectで使う変数の方は,c()で包んでリストにしておく必要あり.
> res = preprocess(iris, + quote(Species=='virginica'), + quote(c(Sepal.Length, Sepal.Width))) > nrow(res) [1] 50 > head(res) Sepal.Length Sepal.Width 1 6.3 3.3 2 5.8 2.7 3 7.1 3.0 4 6.3 2.9 5 6.5 3.0 6 7.6 3.0
これで前処理スッキリ,再利用ブラボー.
おまけ
ちょっと違うアプローチでいうと,以下のようなのもあります*3.
直に指定
preprocess = function(x, column, fn) { fn(x[,column]) }
> preprocess(iris, 'Sepal.Length', max) [1] 7.9
subsetを使う
preprocess = function(df, condition) { e = substitute(condition) r = eval(e, df, parent.frame()) subset(df, r) }
> res = preprocess(iris, Sepal.Length > 7.0) > nrow(res) [1] 12 > head(res) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 103 7.1 3.0 5.9 2.1 virginica 106 7.6 3.0 6.6 2.1 virginica 108 7.3 2.9 6.3 1.8 virginica 110 7.2 3.6 6.1 2.5 virginica 118 7.7 3.8 6.7 2.2 virginica 119 7.7 2.6 6.9 2.3 virginica > ||<
*1:参考: Passing strings as arguments in dplyr verbs - Stack Overflow
*2:NSEについては R - NSEとは何か - Qiitaとか, dplyrのなんたら_eachを効率的に使う - 東京で尻を洗うとか, NSE(Non-Standard Evaluation)について - 東京で尻を洗うの記述が詳しいです.大元は Non-standard evaluationなので,こちらを読むのが良さげです.
*3:参考: r - Pass a data.frame column name to a function - Stack Overflow
BW変換(Burrows Wheeler Transform)を書いた
「高速文字列解析の世界」を読んでて,BW変換のところがよくわからなかったので,実際に書いてみました.
")
高速文字列解析の世界――データ圧縮・全文検索・テキストマイニング (確率と情報の科学)
- 作者: 岡野原大輔
- 出版社/メーカー: 岩波書店
- 発売日: 2012/12/27
- メディア: 単行本
- 購入: 15人 クリック: 324回
- この商品を含むブログ (5件) を見る
概要
BW変換ってなんぞやを一言でいうと,「変換すると,似たような記号がたくさん並ぶようになる,文字列の可逆変換」です.具体例をみせると,以下はWikipediaのBW変換の最初のパラグラフを,実際にBW変換してみた結果です.
元の文章*1
Compression techniques work by finding repeated patterns in the data and encoding the duplications more compactly. The Burrows Wheeler transform (BWT, also called block-sorting compression) rearranges a character string into runs of similar characters. This is useful for compression, since it tends to be easy to compress a string that has runs of repeated characters by techniques such as move-to-front transform and run-length encoding. More importantly, the transformation is reversible, without needing to store any additional data. The BWT is thus a free method of improving the efficiency of text compression algorithms, costing only some extra computation.
変換後の文章*2
mee....ssssyn,amehodksoadreotgra,eleeedheylatefsgnTseesstdssygd) fgsdsof,yorasyntfgngg, ssygrtes,s. nTsnyeonkegaysn ( $ WW BB t r trrrp n c rrrrt lhhhe hehddeemtcp i inu eeionn aaaaneenoen anoeodn hhrrhhbhmrcehlvr ppttltternh se itlrrtltttvguurrrrrmrt ooooef sss -ennnnnnnnnnlnctccc tTTttttWTtcctttslfcms sftrtdrdvdd stssstttnnh rwdrcauibl-eapabanttrrro i oioooooiohoooioouooieeeaaie iiiiiiiiiaehhorouuaaaoaiatsttttlhcc scccCccciiiiiii irftmMgwfffpschmrrm eeummmmmmmmiiaoeetaaartttooo f ppppp ttoooooefpraueeeoo weusrninanniaeidiemrunnnr ssssl -eeeeeo axauinaaru aa ctcc g iei rsaaianc n -sx ssasqqfrrrdBh opoeo oeenbclbsll
ということで,変換すると同じような記号がダーっと並んでるのが見て取れると思います.これの何が嬉しいかというと,同じような文字が連続していると,文字列を圧縮するときに圧縮効率が良くなります*3.
実装
ということで,BWTをするのと,元に戻すのを実際に実装してみました.とはいえ理解のための実装なので,パフォーマンスについては度外視してます.あと,終端文字として$を使っているので,文章中に$があるとうまく変換できません.
これを実際に実行してみると,以下のように可逆に変換されました.
python bwt.py abracadabra ard$rcaaaabb abracadabra
本の簡潔データ構造とかちゃんと読んでから,もう一回パフォーマンスチューニングしますかね...
参考
詳しい説明やパフォーマンス改善については,以下の2つの記事を読んでもらえるとよいと思います.特にLFマッピングの部分は,コードだけだと意味がわからない筈...
*1:実はハイフンがうまく処理できなかったので,「Burrows-Wheeler transform」を「Burrows Wheeler transform」にこっそりと変えてあります.
*2:blogのフォーマットにキレイに収まるように,半角スペースを3個くらい付け加えてあります.
*3:wikipediaにあるように実際にbzip2の圧縮アルゴリズムの中で使われています.
データビジネス・分析・開発に関して2014年に読んだ本
年末なのでぼちぼち今年の振り返りをします.ちなみに去年のはこちら.
データブジネス,データ分析,ソフトウェア開発の3カテゴリに分けて,それぞれについて上から読んでよかった順に並んでいます.
データビジネス
"超"分析の教科書

- 作者: 日経ビッグデータ
- 出版社/メーカー: 日経BP社
- 発売日: 2014/11/17
- メディア: 単行本
- この商品を含むブログ (2件) を見る
アルゴリズムが世界を支配する
")
- 作者: クリストファー・スタイナー
- 出版社/メーカー: KADOKAWA / 角川書店
- 発売日: 2013/10/10
- メディア: Kindle版
- この商品を含むブログ (9件) を見る

- 作者: マイケルルイス,Michael Lewis,渡会圭子,東江一紀
- 出版社/メーカー: 文藝春秋
- 発売日: 2014/10/10
- メディア: 単行本
- この商品を含むブログ (5件) を見る
夜の経済学

- 作者: 飯田泰之,荻上チキ
- 出版社/メーカー: 扶桑社
- 発売日: 2013/09/26
- メディア: 単行本
- この商品を含むブログ (14件) を見る
サイレント・ニーズ

サイレント・ニーズ――ありふれた日常に潜む巨大なビジネスチャンスを探る
- 作者: ヤン・チップチェイス,サイモン・スタインハルト,福田篤人
- 出版社/メーカー: 英治出版
- 発売日: 2014/03/18
- メディア: 単行本
- この商品を含むブログ (1件) を見る
快感回路
")
快感回路---なぜ気持ちいいのか なぜやめられないのか (河出文庫)
- 作者: デイヴィッド・J・リンデン,岩坂彰
- 出版社/メーカー: 河出書房新社
- 発売日: 2014/08/06
- メディア: 文庫
- この商品を含むブログ (1件) を見る
振り込め犯罪結社

- 作者: 鈴木大介
- 出版社/メーカー: 宝島社
- 発売日: 2013/11/22
- メディア: 単行本
- この商品を含むブログ (4件) を見る
インタフェースデザインの心理学

インタフェースデザインの心理学 ―ウェブやアプリに新たな視点をもたらす100の指針
- 作者: Susan Weinschenk,武舎広幸,武舎るみ,阿部和也
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/07/14
- メディア: 大型本
- 購入: 36人 クリック: 751回
- この商品を含むブログ (28件) を見る
ビジネスモデルの教科書

- 作者: 今枝昌宏
- 出版社/メーカー: 東洋経済新報社
- 発売日: 2014/03/28
- メディア: 単行本
- この商品を含むブログ (2件) を見る
A/B Testing: The Most Powerful Way to Turn Clicks Into Customers

A/B Testing: The Most Powerful Way to Turn Clicks Into Customers
- 作者: Dan Siroker,Pete Koomen
- 出版社/メーカー: Wiley
- 発売日: 2013/08/07
- メディア: Kindle版
- この商品を含むブログを見る
最強のWebコミュニケーション・シナリオ

- 作者: 濱川智
- 出版社/メーカー: 日経BP社
- 発売日: 2007/10/18
- メディア: 単行本
- 購入: 5人 クリック: 30回
- この商品を含むブログ (4件) を見る
Lean UX
")
Lean UX ―リーン思考によるユーザエクスペリエンス・デザイン (THE LEAN SERIES)
- 作者: ジェフ・ゴーセルフ,ジョシュ・セイデン,エリック・リース,坂田一倫(監訳),児島修
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/01/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
モバイルフロンティア

モバイルフロンティア よりよいモバイルUXを生み出すためのデザインガイド
- 作者: 安藤幸央,佐藤伸哉,青木博信,清水かほる,野澤紘子,羽山祥樹,脇阪善則
- 出版社/メーカー: 丸善出版
- 発売日: 2013/04/25
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
「ヒットする」「タッチパネル」「レベルアップ」のゲームデザイン

「ヒットする」のゲームデザイン ―ユーザーモデルによるマーケット主導型デザイン
- 作者: Chris Bateman,Richard Boon,松原健二(監訳),岡真由美
- 出版社/メーカー: オライリージャパン
- 発売日: 2009/09/07
- メディア: 単行本(ソフトカバー)
- 購入: 12人 クリック: 116回
- この商品を含むブログ (14件) を見る

「タッチパネル」のゲームデザイン ―アプリやゲームをおもしろくするテクニック
- 作者: Scott Rogers,塩川洋介(監訳),佐藤理絵子
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/08/17
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (3件) を見る

「レベルアップ」のゲームデザイン ―実戦で使えるゲーム作りのテクニック
- 作者: Scott Rogers,塩川洋介(監訳),佐藤理絵子
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/08/18
- メディア: 単行本(ソフトカバー)
- 購入: 17人 クリック: 98回
- この商品を含むブログ (9件) を見る
データ分析
入門リスク分析

- 作者: デビッドヴォース,David Vose,長谷川専,堤盛人
- 出版社/メーカー: 勁草書房
- 発売日: 2003/08
- メディア: 単行本
- 購入: 1人 クリック: 30回
- この商品を含むブログ (8件) を見る
その一方でそうしたリスク分析に関する本は非常に少なくて,本書は非常にわかりやすく,かつ丁寧にまとめられていてとても良いです.本の中頃には,主要な確率分布のまとめもあって,地味にこれがリファレンス的に結構便利だったりします.惜しむらくは,値段が高いのと,すでに廃刊になっていて中古でしか手に入らない点です... と思ってたらいつの間にかKindle版が出てますね.とはいえ¥14,910ととってもお高いですが...
予測にいかす統計モデリングの基本
")
予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで (KS理工学専門書)
- 作者: 樋口知之
- 出版社/メーカー: 講談社
- 発売日: 2011/04/07
- メディア: 単行本(ソフトカバー)
- 購入: 9人 クリック: 180回
- この商品を含むブログ (10件) を見る
応用のための確率論入門

- 作者: 中塚利直
- 出版社/メーカー: 岩波書店
- 発売日: 2010/06/19
- メディア: 単行本(ソフトカバー)
- 購入: 2人 クリック: 16回
- この商品を含むブログ (3件) を見る
数学は言葉

- 作者: 新井紀子,上野健爾・新井紀子
- 出版社/メーカー: 東京図書
- 発売日: 2009/09/07
- メディア: 単行本
- 購入: 152人 クリック: 5,019回
- この商品を含むブログ (29件) を見る
これなら分かる最適化数学

- 作者: 金谷健一
- 出版社/メーカー: 共立出版
- 発売日: 2005/09/01
- メディア: 単行本
- 購入: 29人 クリック: 424回
- この商品を含むブログ (41件) を見る
プログラマのための線形代数

- 作者: 平岡和幸,堀玄
- 出版社/メーカー: オーム社
- 発売日: 2004/10
- メディア: 単行本
- 購入: 27人 クリック: 278回
- この商品を含むブログ (89件) を見る
")
まずはこの一冊から 意味がわかる線形代数 (BERET SCIENCE)
- 作者: 石井俊全
- 出版社/メーカー: ベレ出版
- 発売日: 2011/06/22
- メディア: 単行本
- 購入: 1人 クリック: 5回
- この商品を含むブログを見る
科学と証拠

- 作者: エリオット・ソーバー,松王政浩
- 出版社/メーカー: 名古屋大学出版会
- 発売日: 2012/10/17
- メディア: 単行本
- 購入: 5人 クリック: 105回
- この商品を含むブログ (16件) を見る
手を動かしながら学ぶ ビジネスに活かすデータマイニング

- 作者: 尾崎隆
- 出版社/メーカー: 技術評論社
- 発売日: 2014/08/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
ビジネス活用で学ぶデータサイエンス入門

- 作者: 酒巻隆治,里洋平
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2014/06/25
- メディア: 単行本
- この商品を含むブログ (1件) を見る
エンジニアのための データ可視化[実践]入門
![エンジニアのための データ可視化[実践]入門 ~D3.jsによるWebの可視化 (Software Design plus)](http://ecx.images-amazon.com/images/I/51kgB5g91EL._SL160_.jpg "エンジニアのための データ可視化[実践]入門 ~D3.jsによるWebの可視化 (Software Design plus)")
エンジニアのための データ可視化[実践]入門 ~D3.jsによるWebの可視化 (Software Design plus)
- 作者: 森藤大地,あんちべ
- 出版社/メーカー: 技術評論社
- 発売日: 2014/02/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
データ分析支えるスマホゲーム開発

データ分析が支えるスマホゲーム開発 ~ユーザー動向から見えてくるアプリケーションの姿~
- 作者: 越智修司,高田敦史,丸山弘詩
- 出版社/メーカー: インプレスジャパン
- 発売日: 2014/04/11
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (3件) を見る
実践機械学習システム

- 作者: Willi Richert,Luis Pedro Coelho,斎藤康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/10/25
- メディア: 大型本
- この商品を含むブログ (1件) を見る
データサイエンス講義

- 作者: Rachel Schutt,Cathy O'Neil,瀬戸山雅人,石井弓美子,河内崇,河内真理子,古畠敦,木下哲也,竹田正和,佐藤正士,望月啓充
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/10/25
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
戦略的データサイエンス入門

戦略的データサイエンス入門 ―ビジネスに活かすコンセプトとテクニック
- 作者: Foster Provost,Tom Fawcett,竹田正和(監訳),古畠敦,瀬戸山雅人,大木嘉人,藤野賢祐,宗定洋平,西谷雅史,砂子一徳,市川正和,佐藤正士
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/07/19
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (3件) を見る
日本語入力を支える技術
")
日本語入力を支える技術 ?変わり続けるコンピュータと言葉の世界 (WEB+DB PRESS plus)
- 作者: 徳永拓之
- 出版社/メーカー: 技術評論社
- 発売日: 2012/02/08
- メディア: 単行本(ソフトカバー)
- 購入: 14人 クリック: 322回
- この商品を含むブログ (34件) を見る
現代思想2014年6月号

現代思想 2014年6月号 特集=ポスト・ビッグデータと統計学の時代
- 作者: 西垣通,ドミニク・チェン,竹内啓,小島寛之,津田敏秀,樫村愛子,西川アサキ
- 出版社/メーカー: 青土社
- 発売日: 2014/05/26
- メディア: ムック
- この商品を含むブログ (4件) を見る
ベイズ統計の理論と方法

- 作者: 渡辺澄夫
- 出版社/メーカー: コロナ社
- 発売日: 2012/03
- メディア: 単行本
- 購入: 1人 クリック: 4回
- この商品を含むブログ (2件) を見る
ソフトウェア開発
ZooKeeperによる分散システム管理

- 作者: Flavio Junqueira,Benjamin Reed,中田秀基
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/10/08
- メディア: 大型本
- この商品を含むブログ (1件) を見る
Hadoopオペレーション

- 作者: Eric Sammer,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/11/27
- メディア: 大型本
- この商品を含むブログ (4件) を見る
サーバ/インフラエンジニア養成読本 ログ収集〜可視化編
![サーバ/インフラエンジニア養成読本 ログ収集〜可視化編 [現場主導のデータ分析環境を構築!] Software Design plus](http://ecx.images-amazon.com/images/I/61rZ7L4Zt1L._SL160_.jpg "サーバ/インフラエンジニア養成読本 ログ収集〜可視化編 [現場主導のデータ分析環境を構築!] Software Design plus")
サーバ/インフラエンジニア養成読本 ログ収集〜可視化編 [現場主導のデータ分析環境を構築!] Software Design plus
- 出版社/メーカー: 技術評論社
- 発売日: 2014/08/14
- メディア: Kindle版
- この商品を含むブログを見る
体系的に学ぶ 安全なWebアプリケーションの作り方

体系的に学ぶ 安全なWebアプリケーションの作り方 脆弱性が生まれる原理と対策の実践
- 作者: 徳丸浩
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2011/03/03
- メディア: 大型本
- 購入: 119人 クリック: 4,283回
- この商品を含むブログ (143件) を見る
教養としてのコンピュータ・サイエンス
")
教養としてのコンピュータ・サイエンス (Information Science&Engineering)
- 作者: 渡辺治
- 出版社/メーカー: サイエンス社
- 発売日: 2001/10
- メディア: 単行本
- クリック: 19回
- この商品を含むブログ (2件) を見る
ふつうのLinuxプログラミング

ふつうのLinuxプログラミング Linuxの仕組みから学べるgccプログラミングの王道
- 作者: 青木峰郎
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2005/07/27
- メディア: 単行本
- 購入: 35人 クリック: 450回
- この商品を含むブログ (146件) を見る
アンダースタンディング・コンピュテーション

アンダースタンディング コンピュテーション―単純な機械から不可能なプログラムまで
- 作者: Tom Stuart,笹田耕一(監訳),笹井崇司
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/09/18
- メディア: 大型本
- この商品を含むブログ (5件) を見る
Web+DB PRESS Vol.82

- 作者: 山口徹,Jxck,佐々木大輔,横路隆,加来純一,山本伶,大平武志,米川健一,坂本登史文,若原祥正,和久田龍,平栗遵宜,伊藤直也,佐藤太一,高橋俊幸,海野弘成,五嶋壮晃,佐藤歩,吉村総一郎,橋本翔,舘野祐一,中島聡,渡邊恵太,はまちや2,竹原,河合宜文,WEB+DB PRESS編集部
- 出版社/メーカー: 技術評論社
- 発売日: 2014/08/23
- メディア: 大型本
- この商品を含むブログ (1件) を見る
Web+DB PRESS Vol.77

- 作者: 中川勝樹,山内沙瑛,舟崎健治,吉荒祐一,今井雄太,八木橋徹平,安川健太,近藤宇智朗,奥野幹也,天野祐介,賈成カイ,伊藤直也,住川裕岳,北川貴久,菅原一志,後藤秀宣,久森達郎,登尾徳誠,渡邊恵太,中島聡,A-Listers,小俣裕一,はまちや2,川添貴生,石本光司,舘野祐一,沖田邦夫,澤村正樹,卜部昌平,吉藤博記,片山暁雄,平山毅,WEB+DB PRESS編集部
- 出版社/メーカー: 技術評論社
- 発売日: 2013/10/24
- メディア: 大型本
- この商品を含むブログ (3件) を見る
JavaScriptエンジニア養成読本
![JavaScriptエンジニア養成読本[Webアプリ開発の定番構成Backbone.js+CoffeeScript+Gruntを1冊で習得!]](http://ecx.images-amazon.com/images/I/51FqxHiDfcL._SL160_.jpg "JavaScriptエンジニア養成読本[Webアプリ開発の定番構成Backbone.js+CoffeeScript+Gruntを1冊で習得!]")
JavaScriptエンジニア養成読本[Webアプリ開発の定番構成Backbone.js+CoffeeScript+Gruntを1冊で習得!]
- 作者: 吾郷協,山田順久,竹馬光太郎,和智大二郎
- 出版社/メーカー: 技術評論社
- 発売日: 2014/12/11
- メディア: Kindle版
- この商品を含むブログを見る
パーフェクトJavaScript
")
パーフェクトJavaScript (PERFECT SERIES 4)
- 作者: 井上誠一郎,土江拓郎,浜辺将太
- 出版社/メーカー: 技術評論社
- 発売日: 2011/09/23
- メディア: 大型本
- 購入: 24人 クリック: 588回
- この商品を含むブログ (12件) を見る
インフラエンジニアの教科書

- 作者: 佐野裕
- 出版社/メーカー: シーアンドアール研究所
- 発売日: 2013/10/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (11件) を見る
エキスパートPythonプログラミング

- 作者: Tarek Ziade,稲田直哉,渋川よしき,清水川貴之,森本哲也
- 出版社/メーカー: アスキー・メディアワークス
- 発売日: 2010/05/28
- メディア: 大型本
- 購入: 33人 クリック: 791回
- この商品を含むブログ (91件) を見る
その他
駆け出しマネージャーの成長論
")
駆け出しマネジャーの成長論 - 7つの挑戦課題を「科学」する (中公新書ラクレ)
- 作者: 中原淳
- 出版社/メーカー: 中央公論新社
- 発売日: 2014/05/09
- メディア: 単行本
- この商品を含むブログ (6件) を見る
現役・三井不動産グループ社員が書いた! やっぱり「ダメマンション」を買ってはいけない

現役・三井不動産グループ社員が書いた! やっぱり「ダメマンション」を買ってはいけない
- 作者: 藤沢侑
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2013/03/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
おわりに
今年は分析に関する本とか読んでない気がします.来年はちゃんと論文読むか,もう少し違う分野のデータ関連本*2を読むか,とかをしようかなと思っていたりします.あと,そもそも本よりもWeb上の文献を参考にしている量のほうが多いと思うし,いい加減本のレビューをまとめをするのも結構意味が薄いなぁと思い始めているたりもします.
*1:私自身はこの本は未読ですが,マイケル・ルイスだと世紀の空売りとかライアーズ・ポーカーあたりが滅茶苦茶スリリングで面白かったです.
*2:医療統計とか,経済系とか,異分野の手法を知っておいたほうがいい気がしている今日この頃です.
PythonのnimfaでNMFを試す
PythonでNMFやるには,nimfaというパッケージを使えばよいらしいです.とりあえず使うだけなら,適当なnumpy行列vecを用意して,以下のように関数に投げてあげます.
factor = nimfa.mf(vec, seed='random_vcol', method='nmf', rank='5', max_iter=10) res = nimfa.mf_run(factor).basis()
とりあえずシードはランダムで,手法はベーシックなnmf.何次元に削減するかをrankで指定して,イテレーション回数を決めればOKです.
nmfは関連手法が山ほどあって,ざっと以下のようになります.説明文は基本的に意訳です.正直意訳があってるかも自信はないので,こちらから元論文を読みましょう*1.
| 手法 | 概要 |
|---|---|
| BD | ギブスサンプラーを使ったベイジアンNMF |
| BM | バイナリのMF |
| ICM | Iterated conditional modesを用いたNMF*2 |
| LFNMF | 局所特徴量を用いたフィッシャーのNMF |
| LSNMF | 最小二乗法を用いたNMF |
| NMF | 通常のNMF(更新式としてユークリッド/KL情報量,損失関数としてFrobenius/divergence/connectivityが指定可能) |
| NSNMF | non-smoothなNMF |
| PMF | 確率的NMF |
| PSMF | 確率的スパースMF |
| SNMF | 最小二乗制約に基づく非負性を用いたスパースNMF |
| SNMNMF | スパース正則化ネットワークNMF |
| PMFCC | 制約クラスタリングによる罰則MF |
ということで,実際に回してみました.前回のマンションポエムデータ,218サンプル*1797次元のデータを10次元に圧縮します.これを10回繰り返して得られた10の圧縮行列に対して,適当なidを選んで類似度上位10件のデータを抜き出し,その一致度を集計しました.
結果は以下の通りで,時間がかかるものほど一致率も高く安定的な結果ということのようです.とはいえ安定しているから結果が良いかというと,パッとみた感じそんなに手法ごとに精度の差が歴然としているかといわれると,若干首をひねらざるを得ない感はあります*3.にしても,全体的に安定性はイマイチです... そしてBDとかPMFとかは,とにかく重すぎてパパッと結果も帰ってこず.まぁギブスサンプラーとか使ってたら思いに決まってるわけですが...
| 手法 | 一致度 | NMFの算出にかかった時間 [秒] |
|---|---|---|
| NMF | 16.7% | 0.45秒 |
| LSNMF | 30.4% | 0.94秒 |
| BMF | 17.8% | 0.33秒 |
| SNMF | 40.7% | 47.95秒 |
もう少しちゃんとパラメタとかチューニングしないといけないなぁという思いしかない.
マンションポエムで新築マンションをクラスタリング
今回は自然言語処理の話です.それも若干不自然な言語のマンションポエムが対象になります.マンションポエムというのは,工場萌え*1の著者大山さんが提唱している,マンション広告に入っている詩的なコピーのことです*2.具体的にはこんな感じのやつです*3.
PLATINUM SHIP ここは、東京の暮らしの新しき起点。
そこは、時空をかける東京。 TOKYO NON DISTANCE
データ
さて,そんなマンションポエムですが,実はデータが公開されておりまして,先述の大山さんがGoogle Mapにまとめていらっしゃいます*4.このデータ,KMLという三次元地理情報を扱うためのXMLベースのマークアップ言語で,Pythonで適当にパースしてあげれば扱いやすいデータに落とし込むことができます.
ということで早速加工してみたんですが,結構データの抜けや欠けがあって,実は割りと地道に手を動かさないといけないことが判明しました.緯度経度とマンションポエムについては,全てのマンションについてあるのですが,1/3くらいは分譲時期や物件価格が入っていません.特に物件価格は注視したいところなので,いちいちググって手で入力するという作業を繰り返しました.マンションの公式サイトは,大半のものが全物件成約した段階で消されてしまうため,過去に分譲された物件は定番のマンションコミュニティのほか,こちらやこちらといった,個人で実際の広告や価格表をまとめている方のものを参考に大まかな価格を入れていきました*5*6.
あと全然関係ないですが,マンションコミュニティといえばこの覆面座談会,めっちゃ面白いです.
そんなこんなで,おおむね2005年以降に建設されたマンション218件を対象として,マンションポエムを分析しました.
いろいろと前処理
やったこと自体は非常にベーシックで,手作業で作成した辞書を使ってポエムを形態素解析して,名詞/動詞/形容詞だけを取り出して*7,ストップワード*8を削除した上で,LDAにかけてトピックを抜き出しました.
形態素解析
定番の形態素解析エンジンMeCabを使って,ざっくりと形態素に分けます.Pythonバインディングを使って,以下のようにざーっと処理を行っていきます.
tagger = MeCab.Tagger() node = tagger.parseToNode(sentence) # 対象の文字列を読み込んで解析する words = [] while node: features = node.feature.split(",") # 解析結果をカンマで区切って取り出す if features[0] in ['名詞', '動詞', '形容詞']: # 名詞と動詞と形容詞だけが対象 word = node.surface.decode('utf-8') if features[6] == '*' else features[6] # 活用語の場合は基本形を取り出す words.append(word.lower()) node = node.next
辞書
ここが地味に一番だるかったところで,上記の形態素解析をうまく動かすためには,ただしく形態素に分けられないといけないわけです.しかしマンションポエムはかなり妙な日本語を使っており,一般的な日本語辞書だけではうまく分割できない例が多々あります.例えば「駅徒歩圏」ですが,普通に形態素解析してしまうと「駅」「徒歩」「圏」に分かれてしまいます.これは「駅徒歩圏」ではじめて意味をなす単語なので,分割されてしまっては困ります.他にも「庭苑」「緑景」「美邸」「逸邸」といった造語に近いような単語が頻発するので,これを逐一辞書に登録していく必要があります.今回の単語をまとめた辞書は,githubに公開しているので,もし使いたい方がいらしゃればご自由にどうぞ.
同様に「神保町」や「幕張ベイタウン」みたいな地名も,ちゃんと辞書登録してあげないと無残に分割されてしまいますので,これもセコセコと手作業で登録します.地味ですがこれが一番精度に効いてくる気がしています.今回は面倒なので,動詞に関しては辞書登録するのをサボってしまいましたが*9,例えばマンションポエム頻出語として「手に入れる」があって,これが「手」「に」「入れる」に分割されてしまうと,全然ダメだったりします...
モデル作成とクラスタリング
Latent Dirichlet Allocation (LDA) によるトピックモデルの作成
上記前処理を経て形態素に分けられたマンションポエムを,bug-of-words*10のベクトルに直して,LDAにかけてトピックを抜き出します.このあたりはgensimパッケージを使ってやってしまいました.パッケージ自体の使い方は,ゆうくさんの記事やsucroseさんの記事をご覧ください.またLDAの理論的な解説については,例によってあらびきさんの解説を読んでいただくのが良いと思います.
この処理の意味するところをざっくりとまとめると,たくさんの文書から,文書間に共通するいくつかの潜在的なトピックを抜き出す,というようなことをしています*11.このトピックを使ってクラスタリングを行います.コード的には以下のような感じになります.
# 辞書の作成 dictionary = corpora.Dictionary(words) dictionary.filter_extremes(no_below=10, no_above=0.4) # コーパスの作成 corpus = [self._dictionary.doc2bow(w) for w in words] # bag of words corpus = models.TfidfModel(corpus)[corpus] # apply tf-idf corpora.MmCorpus.serialize(corpus_path, corpus) # save serialize data # LDAモデルの作成 model = models.LdaModel(corpus=corpus, num_topics=20, id2word=dictionary)
Gaussian Mixture Model (GMM) によるクラスタリング
上記のLDAによるトピックは,実質的には次元削減と似た効果を持ちます.各ポエムにおける文章の出現数をまとめたベクトル(今回の例だと約1700個の単語があったため,1700次元になります)から20個程度のトピックを抜き出すことは,1700次元を20次元に圧縮することとほぼ同義です.そこで,LDAにより得られた20次元のベクトルを用いて,マンションポエムのクラスタリングを行います.別にk-meansでもいいんですが*12,今回はGMMによるクラスタリングを行いました.GMMの理屈についてはsleipnir002さんの解説をご覧ください.いくつかクラスタ数を試した結果,4つが良さげであることがわかりました*13.
可視化
坪単価 × 都心からの距離
ということで,作成した4つのクラスタについて,あとはRにかませてざっと集計&可視化してみました.dplyr使ってパイプっぽく処理して,クラスタごとのサンプル数,平均坪単価,都心からの距離平均(km)*14をまとめたのが以下になります.クラスタ1が最大派閥で90サンプル,価格はクラスタ0が平均坪単価277万でトップ*15,距離もクラスタ0と3が10km程度でした.
> # summarize > data %>% + group_by(cluster_id) %>% + summarize(n=n(), + price.mean=mean(price), + distance.mean=mean(distance)) Source: local data frame [4 x 4] cluster_id n price.mean distance.mean 1 0 35 277.0857 10.62453 2 1 90 257.3667 13.93625 3 2 47 228.8511 13.91467 4 3 46 255.6522 10.02251
続いて散布図に全サンプルをプロットしてみました.比較的綺麗に,都心からの距離と坪単価が逆相関しているのがみて取れます.一部に坪単価600万とか800万とかあるのは,いわゆる億ションなので,本当は外れ値にしちゃった方が良いかもですけどね... クラスタごとにみても,そこまではっきりとではないですが,まぁそこそこは綺麗に区分けされているかなぁと思います.

クラスタごとのワードクラウド
続いて,今回の素性ベクトルを作るもととなったマンションポエム形態素を可視化するために,ワードクラウドを作成します.これはTagexedoというサービスを使いました*16.現状日本語で自由な文字列からワードクラウドを作れるのは,このサービスしかないっぽいです.
ということで,各クラスタの形態素をワードクラウド化してみた結果が以下の通りです.
クラスタ0
もっとも平均坪単価が高く,都心からの距離が近いだけあって,「都心」「高台」「空」「空間」などの,都心の閑静な高級住宅地や超高層のタワーマンションなんかを表していそうなワードが並んでいます.他には「世界」「美」「上質」といったいかにもなワードも散りばめられています.

クラスタ1
こちらはもっとも都心から遠いクラスタだけあって,「住」「街」「暮」「生活」といった,そこでの具体的な地に足のついた生活をイメージさせるような単語が並んでいます.他にも「家族」「快適」「自然」「伝統」といったワードが並びます.「伝統」「継承」といった言葉は,おおむね古いランドマークがあるような場所なので(例えば浅草や鎌倉のような場所ですね),都心から離れた高級住宅地も含まれている感じがします.

クラスタ2
最も坪単価が安いだけあって,物件ではなく「家族」が一番大きな言葉となっています.家族生活に適した郊外の住宅地,というイメージでしょうか.トップ3が「家族」「暮らし」「住まい」となっているのが,いかにもという感じです.「レジデンス」については,以下のような文言が典型的な使われ方です.
風と緑のレジデンス「×××」*17駅徒歩8分、賑わいの先に広がる住宅地。駅近ながら住宅地の空気に包まれた、家族の暮らしがここから始まる。都市の利便性を手中にしながら、開放的で落ち着きに満たされたこの地。家族を優しく包み込む、ゆとりを育む、この地ならではのレジデンスを創り上げます。住宅地の最前席に住まう駅徒歩圏では限られた、第一種住居地域。


終わりに
まずは,改めて大山さんにお礼を申し上げます.元となるデータがあることの意義は本当に大きいです*18.
そして今回のネタに関連して,いくつか検討したところとか,まだできそうなこととかがあるので,そのうち続きを書こうかなと考えています.このネタを書くために19日から冬休みに入ってて,ようやく今日これが仕上がりました.とはいえ,まだ一般的な冬休みの初めにすらさしかかっていないので,冬休み使ってもう1つ2つできないかなーとか... 本当はこのデータを加工して簡単なWebサービスにしようかと思ってたので,気が向いたらそれやります.あとデベロッパーとか物件の戸数とか階数とかのデータをまとめたら,もう少し面白いことできないかなと思ったり...
*1:私自身,この本を読んで工場夜景クルーズに行ったりもしました.夜の工場いいですよね.FFでいうと7のミッドガルみたいな感じで素敵です.
*3:個人的にマンション広告が好きで,いつの日からかマンション建設予定地に光の柱が立つようになったのを微笑ましくみていたりします.
*4:このデータ作成にかかった多大な労力に,感謝の意を表しつつ利用させていただきます.
*5:物件の広さに影響されるとアレなので,実際にはマンションの価格ではなく,坪単価の形でまとめています.
*6:もちろん同じ物件でも,高層階の東南角地と低層階の形が悪い部屋とでは価格が異なるわけで,複数の坪単価がある場合には,概ね真ん中くらいの数字を使うようにしています.
*7:今回のマンションポエムだと,助詞や副詞がほとんど意味をなさなそうなので無視した,というだけの話で,全ての場合で削除するべきだ,ということではありません.
*8:あまりに一般的すぎるので,実際に自然言語処理を行うときの妨げとなるワードのことです.googleでも,英単語の"a"や"the", "for"なんかは検索の際にストップワードとして無視されています.
*9:動詞や形容詞だと,すべての活用形をちゃんと登録してあげないといけないのですが,これが1語につき10くらいの活用形を登録する必要があって大層面倒なのです.
*10:単語の並び方は考慮せず,単に文章に単語が含まれているかどうかだけをみて,その回数を数字とした形です.
*11:因子分析で,各パラメタの背後にある共通因子を抜き出す,というのと同じイメージかなと思います.まぁモデルの数理的な形は全く違いますが...
*12:とはいえ実際のところはk-meansは精度悪いんで,あんま使いたくはないってことなんですけどね...
*13:5個以上だと似たようなクラスタがいくつもできたり,サンプル数が極端に少ないものができたり,でイマイチだったので...
*14:ここでは都心として皇居の緯度経度(35.6825° N, 139.7521° E)を用いています.ある程度の目安にしかなりませんが,まぁそこは目を瞑ってください.
*15:坪単価が想像できない人のために補足すると,坪単価277万のマンションというのは,親子4人で住むような70平米のマンションで5876万円!! もする価格です.新築マンションってタカイデスネー
*16:利用するためにはMS Silverlightが必要で,しかもChromeだと動きません...
*17:具体的な物件名は特定できない形にしておきます
*18:とはいえ草の根でデータまとめるの本当に大変なので不動産屋さんとかデータ提供してくれたら嬉しいのになぁとか思っています.まぁ企業側に何のメリットもないから無理でしょうけど...
Yosemiteでのmecabのパス
mecabの辞書作成をしようとしたら,なぜかgooglecodeにある説明とパスが違ってて,探すのに多少苦労したのでメモ.Yosemitenのせいなのか,何か自分がインストールのやり方を間違えたのかはわからないのだけど.
# mecabのディレクトリ /usr/local/Cellar/mecab # ipadic辞書のディレクトリ /usr/local/Cellar/mecab/0.996/lib/mecab/dic/ipadic
そんなわけで,辞書作成コマンドはこんな感じ.権限も管理者権限で入ってたので,sudoつけないとダメだった.
sudo /usr/local/Cellar/mecab/0.996/libexec/mecab -d /usr/local/Cellar/mecab/0.996/lib/mecab/dic/ipadic -u my_dictionary.dic -f utf-8 -t utf-8 my_dictionary.csv