「熊とワルツを」のリスクシミュレーションをRで実装した
最近「熊とワルツを」というプロジェクトにおけるリスク管理についての本を読みました.本の中にでてくるリスク管理シミュレーションをR実装しました,という話です.

- 作者: トム・デマルコ,ティモシー・リスター,伊豆原弓
- 出版社/メーカー: 日経BP社
- 発売日: 2003/12/23
- メディア: 単行本
- 購入: 7人 クリック: 110回
- この商品を含むブログ (150件) を見る
ネタ元のトム・デマルコさんの本は,軽妙な語り口でとても読みやすいので,プロジェクトベースでお仕事する人はみんな一度は目を通してみるといいんじゃないかなと思います*1.偉い人の思いつきで,ケツの決まったプロジェクトを押し付けられそうになったときに,そんなんじゃ崩壊するだろって言い返すためにも*2.そんなわけで,シミュレーションの説明をする前段として,本の中で述べられているリスクについて軽く触れておきます.
5つのコアリスク
この本ではリスク管理について様々な観点から述べられているのですが,その中で主なリスク要素として以下の5つが挙げられています.
- スケジュールの欠陥
- 要求の増大
- 人員の離脱
- 仕様の崩壊
- 生産性の低迷
これらのリスク要因の中でも,4番目に挙げられた「仕様の崩壊」については,これが起こるとプロジェクト自体が崩壊して失敗するものとされています.それ以外の4つについては,発生によってスケジュール自体が5%〜20%のような幅のある見積もりで遅延するものと考えられます.
ツールの概要
ツールの中で実際に行われているのは,スケジュール遅延予測分布に基づいた,モンテカルロシミュレーションです.平たくいうと,スケジュールを実施する人が,いくつかのリスク要素についてあらかじめスケジュール遅延度合いを以下の3点で見積もります.
- スケジュールの最小遅延割合
- スケジュールの最頻遅延割合
- スケジュールの最大遅延割合
これを5つのコアリスクについて見積もります.ただし4番目の「仕様の崩壊」については,これが生じるとプロジェクト自体が失敗してしまうクリティカルなリスクということで,別途以下のように見積もります.
- 仕様崩壊が発生する確率
- 仕様崩壊が生じたときに,プロジェクトが失敗するか否か
- プロジェクトが失敗しない際に遅延する月数
- プロジェクトが失敗しない際に遅延する割合
シミュレーションでは,プロジェクトが失敗しないパターンも見積もることが可能で,その場合は遅延月数もしくは遅延割合のどちらかで,スケジュール遅延を表します.この数字は一般にとても大きくなるものと考えられます.
上記の値を設定した上で,乱数を用いて遅延度合いのサンプルを取得し,実際にどのくらいスケジュールが遅延するか(もしくは失敗するか)を計算します.これを繰り返し実施して,スケジュール遅延度合いの分布を作成します.これによってだいたいスケジュールがどのくらい遅延するかの目安を得ることができます.
Rでの実装
ということでコードをみていきます.フルバージョンはgithubリポジトリを参照してください.コードは設定ファイルと実行ファイルの2つに分かれています.設定ファイルは以下のようになります.
# trial iteration count N_TRIAL = 3000 # project period START_DATE = as.Date("2015/1/1") END_DATE = as.Date("2016/9/30") SPAN = END_DATE-START_DATE # fatal risk: SPECFLAW(failure to reach consensus) FR = list("prob"=0.15, "fatal"=TRUE, "month"=8, "rate"=0) # other risk factors RF = list(1:10, list()) ## RF01: SCHEDFLAW(error in original sizing) RF[[1]] = list("min"=0.0, "mode"=0.2, "max"=0.5) ## RF02: TURNOVER(effet of employee turnover) RF[[2]] = list("min"=0.0, "mode"=0.05, "max"=0.1) ## RF03: INFLATION(requirement function growth) RF[[3]] = list("min"=0.0, "mode"=0.1, "max"=0.2) ## RF04: PRODUCTIVITY(effect of productivity variance) RF[[4]] = list("min"=0.0, "mode"=0.05, "max"=0.2) ## RF05: OTHER RISK RF[[5]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF06: OTHER RISK RF[[6]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF07: OTHER RISK RF[[7]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF08: OTHER RISK RF[[8]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF09: OTHER RISK RF[[9]] = list("min"=0.0, "mode"=0.0, "max"=0.0) ## RF10: OTHER RISK RF[[10]] = list("min"=0.0, "mode"=0.0, "max"=0.0)
4番目の「仕様の崩壊」については,別計算が必要なので"fatal risk"として別途切り出しています.項目は順にリスクの発生確率,発生時にプロジェクトが崩壊するか否か,崩壊しない場合の遅延月数,遅延割合です.「仕様崩壊」がないとする場合には,prob=0としてください.それ以外の4つ+予備の5つのリスク要素について,最小値,最頻値,最大値を割合で入力します.その要素の影響が特にない場合には,3つとも0に設定してください.
それ以外に,プロジェクトの開始日時と終了日時を設定可能です.実際のプロジェクト開始日と終了日を適宜変更して入れてください.またシミュレーションの実行回数は,とりあえず3000回としてありますが,任意に変更可能です*4.本体のriskology.Rを実行すると,結果として以下のように結果が得られます.また "img/histgram_of_delays.png" にヒストグラムが画像で保存されます.ヒストグラムを見るとわかるように,今回の設定だとプロジェクトは最低100日以上,平均して250日程度遅延することがみてとれます.
> sprintf("iteration count: %d", N_TRIAL) [1] "iteration count: 3000" > sprintf("project cancel count with fatal risk: %d", cancelled) [1] "project cancel count with fatal risk: 463" > sprintf("cancel rate: %02.1f%%", cancelled/N_TRIAL*100) [1] "cancel rate: 15.4%" > print("Summary of delay days:") [1] "Summary of delay days:" > summary(delays) Min. 1st Qu. Median Mean 3rd Qu. Max. 108.0 217.0 253.0 254.2 291.0 426.0 >
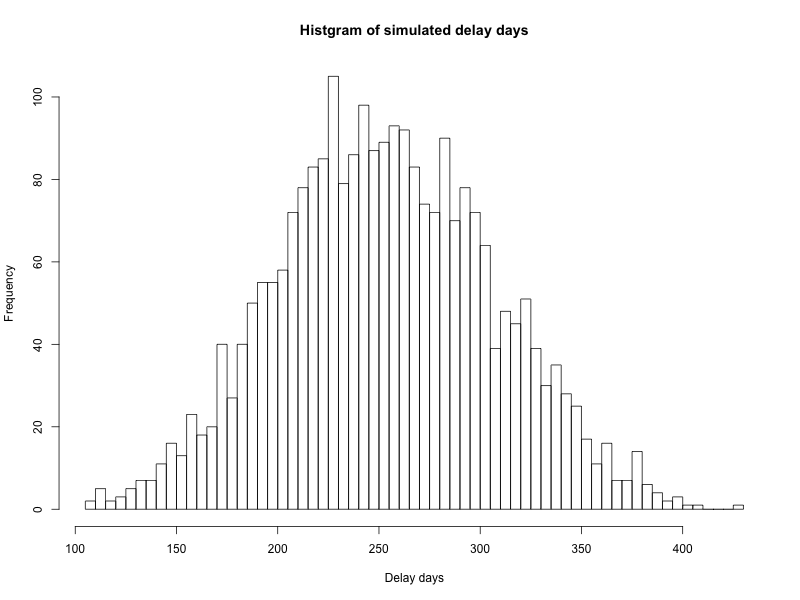
そんなわけで,ちゃんとスケジュール遅延の可能性を分布で把握して,炎上しないように楽しくプロジェクトをこなしていきましょう*5.
最後にそしてシミュレーション本体はこちらです.
source("conf.R") # risk distribution sampler sampler = function(rf_, total=10) { range = rf_[["max"]]-rf_[["min"]] alpha = total*(rf_[["mode"]]-rf_[["min"]])/range beta = total*(rf_[["max"]]-rf_[["mode"]])/range sample = rbeta(1, alpha, beta) sample*range } # calculate fatal risk fatal_risk = function(fr) { if (fr[["prob"]] < runif(1)) { return(0) } else { if (fr[["fatal"]]) { return(-1) } else { month = fr[["month"]]*30 rate = (END_DATE-START_DATE)*fr[["rate"]] return(max(month, rate)) } } } # calculate delay factor delay_factor = function(RF) { df = 0 for (i in 1:length(RF)) { df = df+sampler(RF[[i]]) } df } # calcurate delay cancelled = 0 delays = c() for (i in 1:N_TRIAL) { delay = 0 # check fatal risk fatal = fatal_risk(FR) if (fatal == -1) { cancelled = cancelled+1 next } else { delay = delay+fatal } # add other risk factors for (i in 1:length(RF)) { delay = delay+(END_DATE-START_DATE)*sampler(RF[[i]]) } delays = c(delays, as.integer(delay)) } # draw histgram png("img/histgram_of_delays.png", width=800, height=600) hist(delays, breaks=max(10, as.integer(N_TRIAL/30)), main="Histgram of simulated delay days", xlab="Delay days", ylab="Frequency") dev.off() # print result sprintf("iteration count: %d", N_TRIAL) sprintf("project cancel count with fatal risk: %d", cancelled) sprintf("cancel rate: %02.1f%%", cancelled/N_TRIAL*100) print("Summary of delay days:") summary(delays)