Fitbitから取得した心拍データで時系列の異常検知を試してみる
井出先生の「異常検知と変化検知」を読んで,自分でも試してみたいと思ったんですが,あいにくちょうどいい時系列データが手元にないなーと思ってました.そんな折,データサイエンスLT祭りの発表の中に,Fitbitデータを可視化するものがあって*1,これはちょうどいいということで試してみましたよというていのエントリになります.
")
- 作者: 井手剛,杉山将
- 出版社/メーカー: 講談社
- 発売日: 2015/08/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
Fitbitってなによ
Fitbitが何かしらない人のために一応説明しておくと,最近はやりの活動量計です.私が持っているのは,心拍が取得できるタイプのやつです.風呂に入るとき以外は一日中つけっぱなしで,睡眠とか運動とかを自動で判定してくれるので,手間がかからず便利です.自転車に乗っている時間もちゃんと判定してくれるのは,判定アルゴリズムよくできているなーという感じですね*2.ちなみに運動や睡眠の判定は,データをスマホに転送するタイミングで一気に行われるので,このときに時系列の状態推定アルゴリズムを走らせてるんだろうなぁと思います.その一方で歩数に関しては,手を振ったりしてもほとんどカウントされず,ちゃんと歩いている場合にのみ歩数が増えるところをみると,バンドパスフィルタでも使って地面に足が着地する際のパルス応答的な変化を取ってるんじゃないかなーと推測します*3.

【日本正規代理店品】Fitbit ワイヤレス活動量計+心拍計リストバンド ChargeHR Large Black FB405BKL-JPN
- 出版社/メーカー: Fitbit
- 発売日: 2015/04/24
- メディア: エレクトロニクス
- この商品を含むブログ (7件) を見る
Fitbitのデータを取得する
もちろん,Fitbitの各種センサから得られる生データを取得することはできません.ですがFitbitは開発者向けのAPIを提供しており,ここからデータを取得できるようです.また,もっとベタにWebサイトをスクレイピングしちゃうやり方もあるみたいですね.この辺りをサポートしてくれるパッケージをざっと調べたところ,Rなら fitbitScraper,Pythonなら python-fitbit あたりでしょうか.あとはRなら {httr} パッケージとか使って,OAuthからのAPI直叩きという方法もありそうです.
今回は,普通に {fitbitScraper} を使って,心拍データを取得することにしました.得られるデータは5分間隔のため,1時間で12点,1日で288点になります.以下のようなコードで,適当な日付の心拍データ変動を取得してグラフ化してみました.(fitbitScraper) だけでなく,あとで2軸グラフを記述するために {devtools} 経由で {plotflow} パッケージも入れておきます.(fitbitScraper) は www.fitbit.com へのログインメアドとパスワードが必要なので,持っていない人は取得しておいてください.
install.packages("fitbitScraper") devtools::install_github("trinker/plotflow") library(fitbitScraper) library(plotflow) library(ggplot2) library(dplyr) # Fitbitからのデータ取得 cookie = login(email="www.fitbit.com ログイン用メールアドレス", password="www.fitbit.com ログイン用パスワード") hr_data <- get_intraday_data(cookie, what="heart-rate", date="2016-10-06") names(hr_data) <- c("time", "heart_rate") # 変数名にハイフンが入っているのでリネーム hr_data <- hr_data %>% filter(heart_rate > 0) # Fitbitを取り外しているときは,値が0になるため取り除く # プロット hr_plot <- ggplot(data=hr_data, aes(x=time, y=heart_rate)) + geom_line(size=0.8) + ylim(min=0, max=120) + labs(x="Time", y="Heart rate") + theme(axis.text=element_text(size=14), axis.title=element_text(size=16, face="bold")) plot(hr_plot)
明け方の寝ている時間は心拍数が50弱/分で推移しており,起きてから犬の散歩にいったので100くらいまで上がっています.そのあとは通常の動きで,夕方前くらいにサイクリングにいったため,やはり100をコンスタントに超えています.そして24時に近づくにつれ心拍が落ち着いていくのが見て取れます.

こんな感じで,Fitbitのデータは割と簡単に取得できます.
特異スペクトル変換法による時系列データの異常検知
今回使うデータは,時系列の心拍データになります.ここで目的としたいのは,それまでの時間と比べて明らかにおかしな動きがみられたとき,つまり変化点を検知したいということです.井出先生の本にもいくつかの手法が解説されていますが,今回はその中で特異スペクトル変換法を取り上げたいと思います.
この手法は,ざっくりいうとある時点tを起点として,その前のw時点分のデータ(これを部分時系列データと呼びます)を1時点ずつ前にずらしていって,それをk個たばねたもの(仮にと呼びます)と,そこからL時点分後ろにずらして同じくk個たばねたもの(
と呼びます)を比較します.両者が似ていれば,t時点で変化は起こっておらず,逆に両者が大きく異なっていたら,t時点付近で時系列データに変化が起こったと考えましょう,ということになります.
このは,1行につきw時点ぶんのデータが並び,それをk行分たばねたk x w行列になります.
も同様です.知りたいのは
と
がどれだけ似ているか,ですが,その前段として,
と
のそれぞれについて,特異値分解で要約し,左特異値ベクトルをm次元分だけ取り出します*4.これにより,時系列の変化を考慮した上で,
と
のそれぞれを要約することができました.
そして得られた2つの特異値について,以下の計算をすることで,最終的な異常値を得ることができます.左辺の第2項は,両者が類似しているほど1に近い値になるので,これを1から引くことで非類似度,つまりこの場合はそれ以前からの変化の度合いを表す値が得られるわけです.
Rで特異スペクトル変換法を実装
さて,それでは実際に計算してみましょう.このあたりの式は,同じく井出先生の「入門機械学習による異常検知」を下敷きにしています.

- 作者: 井手剛
- 出版社/メーカー: コロナ社
- 発売日: 2015/02/19
- メディア: 単行本
- この商品を含むブログ (4件) を見る
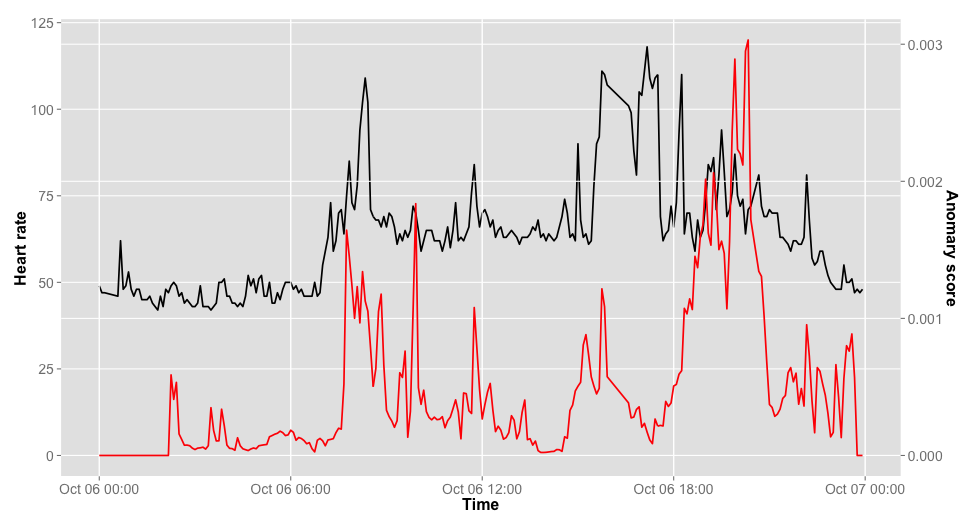
# 定数 w <- 16 # 部分時系列の要素数 m <- 2 # 類似度算出に使用するSVDの次元数 k <- w / 2 # SVD算出に用いる部分時系列数 L <- k / 2 # 類似度を比較する2つの部分時系列群間のラグ # 異常値のスコアを算出するメソッド get_anomaly_score <- function(d, w, m, k, L) { anomaly_score <- rep(0, length(d)) for(t in (w+k):(length(d)-L+1)) { start <- t - w - k + 1 end <- t - 1 X1 <- t(embed(d[start:end], w))[w:1,] # t以前の部分時系列群 X2 <- t(embed(d[(start+L):(end+L)], w))[w:1,] # 異常度算出対象の部分時系列群 U1 <- svd(X1)$u[,1:m] # X1にSVDを行い上位m次元を抜き出す U2 <- svd(X2)$u[,1:m] # X2にSVDを行い上位m次元を抜き出す sig1 <- svd(t(U1) %*% U2)$d[1] # U1とU2の最大特異値を取得 anomaly_score[t] <- 1 - sig1^2 # 最大特異値の2ノルムを1から引くことで異常値を得る } anomaly_score } # スコアを算出して,心拍の時系列と重ねてプロット hr <- hr_data$heart_rate anomaly_score <- get_anomaly_score(hr, w, m, k, L) as_data <- data.frame(time=hr_data$time, anomaly_score=anomaly_score) as_plot <- ggplot(as_data, aes(x=time, y=anomaly_score)) + geom_line(color="red", size=0.8) + labs(title="", x="Time index", y="Anomary score") + theme(axis.text=element_text(size=14), axis.title=element_text(size=16, face="bold")) combined_plot <- ggdual_axis(lhs=hr_plot, rhs=as_plot) plot(combined_plot)
全部で288時点しないので*5,部分時系列の時点数は16くらいに絞っておきます.結果は以下の通りです.おおむね想定したとおりに,変化点が検知できているように思います,ただ後半のサイクリングの変化点が,微妙に後ろにずれちゃっているようにも思います.このあたり,細かいスパイクが悪い影響与えているかもしれないので,スムージングしてからスコアを出したほうがいいのかなぁとも思います.
パラメタのチューニング
上の例では,すべての定数を決めうちにしちゃっているので,いくつかパラメタを変えてどうスコアが変わるかを見ていきたいと思います.ここではwとmについて試してみます.
まずはwからみていきましょう.wを8, 16, 32の3パターンに変えて,スコアを出してみたのが下の図になります.青が8,赤が16,緑が32になります.みるとわかるように,wが増えるほどスコアが減少して,変化を検出しづらくなっています.部分時系列が増えるんだから,当然そうなりますよね.

as_data_w08 <- data.frame(time=hr_data$time, anomaly_score=get_anomaly_score(hr, 8, m, k, L)) as_data_w16 <- data.frame(time=hr_data$time, anomaly_score=get_anomaly_score(hr, 16, m, k, L)) as_data_w32 <- data.frame(time=hr_data$time, anomaly_score=get_anomaly_score(hr, 32, m, k, L)) as_plot_w <- ggplot(as_data_w08, aes(x=time, y=anomaly_score)) + geom_line(color="blue", size=0.8) + geom_line(data=as_data_w16, aes(x=time, y=anomaly_score), color="red", size=0.8) + geom_line(data=as_data_w32, aes(x=time, y=anomaly_score), color="green", size=0.8) + labs(title="", x="Time index", y="Anomary score") + theme(axis.text=element_text(size=14), axis.title=element_text(size=16, face="bold")) combined_plot_w <- ggdual_axis(lhs=hr_plot, rhs=as_plot_w) plot(combined_plot_w)
同様に,mについても1, 2, 3と変えてみてみたのが,以下の図になります.青が1,赤が2,緑が3になります.こちらも同様に,次元数が少ないほど結果がピーキーになってますね.このあたり,元の時系列データの特性に合わせて,適切な次元数を決めてあげる必要がありそうです.

そんなわけで,ライフログデータでいろいろ試してみることができますね.面白い.コードはgistにあげてあるので,よろしければどうぞ.
*1:@millionsmileさんの「チャップが山粕を一撃する方法」という発表なんですが,特に資料は公開されてないみたいですね...
*2:とはいえ,感覚的には15分以上連続で運転するぐらいでないと,サイクリングと判定をしてくれないので,誤判定を防ぐためなんでしょうけど,割と保守的だなーとは思います.
*3:そもそも歩数カウントはオンラインでちゃんとカウントされていくため,時間&空間計算量をそこそこ必要とする時系列の状態推定は厳しそうに思います.なので単純なフィルタリングをしてるだけなんじゃないかなー
*4:ここで特異値分解で得られる左特異値ベクトルのL2ノルムをとると1になります
*5:この日のデータは欠損があるっぽくて,286時点しかありませんでしたが.