マーケットデザインと受入保留アルゴリズム
最近,ブログエントリを書くときの枕が読んだ本のことが多いですが,今回も御多分に洩れずであります*1.
現実の中でのマーケットデザイン
つい先日まで,以下の本を読んでました.マーケットデザインという分野を過分にしてしらなかったんですが,大元はゲーム理論の一種だったんですね.著者のロスさんらが,自身で証明した理論について現実問題に当てはめ,実際にうまく機能することを示した,その過程が描かれていて,非常に面白い本でした.臓器移植や公立学校の希望選択,新米医者の医局配属といった,いわゆるマッチングの問題が,周到に仕組みをデザインすることで,全体的な満足度が高い状態で解決された例をみると,なるほどなーという感想しかでないです.
 ―マッチメイキングとマーケットデザインの新しい経済学")
Who Gets What (フー・ゲッツ・ホワット) ―マッチメイキングとマーケットデザインの新しい経済学
- 作者: アルビン・E・ロス,櫻井祐子
- 出版社/メーカー: 日本経済新聞出版社
- 発売日: 2016/03/19
- メディア: 単行本
- この商品を含むブログ (2件) を見る
この本の中では,主に公共に関わるマーケットのマッチング問題について,主に述べられていました.ですが私自身がこれを読もうと思ったきっかけは,新しいサービスやプラットフォームを構築するときには,マーケットデザインの考え方が割とうまく当てはめられるんじゃないかな,と思ったからです.典型的にはネットオークションは一種のマーケットですし,その流れで今ではメルカリのようなもう少しシンプルな個人売買のプラットフォームも同様だといえます.特にWebを介したB2CやB2B2Cのサービスは,割と多くがマッチング問題に関わるものではないかと思います*2.
そしてこの本の中でくどいくらいに繰り返し言われていたのは,アルゴリズム以外の部分,つまりはそのマーケットがどういう人たちで構成されていて,どういうセンシティブな問題があり,どういった政治的事情が絡んでいるか,といった細部まで踏み込んで緻密なデザインを行わなければ,マーケットはうまく機能しないということでした.さっきのヤフオクやメルカリなんかも,レビュー機能であったり決済代行機能であったり,それ以外にもさまざまな工夫や調整を行うことで,厚みのあるマーケット*3を構築できたのだろうなぁと思います.神は細部に宿るではないんですが,世の中そんなに簡単にスパッと割り切れるものではないということなんだなぁと,なんかしみじみ思ってしまいました.
よくあるマッチング問題
この本の中でメインで述べられていたのが,受入保留アルゴリズムというものです.本中の例だと,よりよい就職先を希望する医者の卵と,よりよい新人を採用したい医局側が,どうやればうまくマッチングするかという話が例として出されていました.なにもせず自由競争に任せてしまうと,他の医局に取られる前に有望そうな新人を先に取ってしまえということで,青田刈りのような状況になってしまいます.その青田刈りが行き着いた先には,まだ専門教育をちゃんと受ける前の段階の学生に対するアプローチ合戦が起こり,やりたいことや能力の評価がうまくできずマッチングミスが逆に増えてしまう,という結果が待っていました*4.
これを防止するために協定が結ばれ,一定期間より前には医局側が採用することができないというルールが決められたりもしましたが,時が経つにつれ内密に口利きがされたりという事例が相次ぎ,なし崩し的に元に戻ってしまう,という状態だったようです*5.このような現象が起こるのは,単純な希望順のマッチングを行うだけだと,一部の人気医局に希望が集中して,第1希望にあぶれてしまったが最後,第2希望も第3希望もすでに埋まってしまっており,希望順位の低いところにいかなければいけない制度のせいだったりします.そうすると,本当の希望順リストを書くよりも,確実にいけそうなところを第1希望にみたいなことが横行することになってしまうわけです.なので,この状態を解決するためには,本心の希望順リストを書いた上で,それが正しく機能するマッチングシステムを作らなければいけないのですね.
受入保留アルゴリズム
そこで出てくる受入保留アルゴリズムは,簡単にいうと,第1希望のマッチングを行った際に,マッチングしたペアの選択がその場で確定するわけではなく,仮のマッチングとして保留しておき,続く第2希望のマッチングでやってきた新たな希望者と合わせて,再度マッチングを行う,というプロセスをとります.つまりこの場合,最初のステップでたとえ第1希望でうまく滑り込めたとしても,より優秀な人が後のステップでその医局を希望してきたら,その人がマッチングすることになります.そして最初に滑り込めてた人は,第2希望の医局にマッチング希望を出すわけです.これを繰り返して,全員がマッチングしたら,その時に初めて結果が確定します.厳密なアルゴリズムについては,このあたりの講義資料でも読んでいただければと思います.
ということで,実際に実装して試してみました.上の例で示した医者-医局マッチングは,複数の対象を選択することができる応用的な問題なので,ここではもっとシンプルに1対1のマッチング問題を試しています.これは
安定結婚問題 - Wikipedia として知られている問題で,例としてお見合いパーティーにおける男性→女性の告白を考えます*6.実際に実行した結果も下に貼っていますが,3回ほど回して,6ステップ,12ステップ,22ステップでそれぞれ10対10のマッチングが安定状態に至りました*7.
そんな感じで,数理的な問題を実問題に落とし込めると楽しいだろうなぁと思った,そんな夜でした.この本はさすがに一般書すぎるので,もう少しメカニズムデザインについてちゃんと書いてある書籍を読みたいですね...何かおすすめあるんでしょうか.
*1:まぁ,お仕事に関する部分で書けるようなことがあまりない,というのが実際のところなのですが.
*2:Web以前からやられてますが,有名なリクルートのリボンモデルなんかは,まさにですよね.未読ですけど,須藤さんのこの記事なんかには,ちゃんとした分析が書いてあるのかなーと思います.
*3:この本の中では,多くのプレイヤーが集まり,活発に取引が行われている状況のことを,「厚みのある」という表現であらわしています
*4:過度な市場信奉者に対しての煽りでもないですが,シンプルな市場メカニズムに任せていれば最善の結果が得られるわけでは,必ずしもないということですね.
*5:なんか我が国の新卒就職市場を見ているようですね.
*6:フェミニズム的な意味で微妙な例だとは思いますが,他にパッとわかりやすい例が思い浮かばなかったので,ご勘弁ください.
*7:そもそも数学的に,このアルゴリズムは必ず安定状態に至ることが証明されています.ただ安定ではあるが,最善の結果とは限らない点はポイントです.正確には,voter側にとって最高,picker側にとって最悪の形で安定状態になります.
上司をマネジメントする (Managing your boss)
先日のETLの記事の中でも軽く触れたんですが,ホントの意味でデータが組織で活用されるためには,組織全体がデータを使って意思決定をする組織構成になっていないといけない,というのが最近強く感じることです.キンボール先生の本では,このあたりビジネスサイドのキーパーソンを必ず巻き込めと書かれているわけですが,逆にいうとそれしか書いてなかったりします.そんな折,TLでユウタロスさんが以下のようなツイートをしていました.
上司をマネジメントするという視点については、Managing Your Boss という論文で研究もされており、知人のハーバードビジネススクール出(本物)の経営者も在学中に読んでいたく感銘を受けたと言ってました。有効だと僕も思います。https://t.co/3gtnDiecJP
— ユウタロス Ver.1.3.4 (@bishop_ring) 2016年3月26日
データドリブンな組織を作るというのは,まさに組織のトップを抱き込んで動かしていくわけで,つまりは自分の上司やその上司,さらにその上司にまで首を縦に振らせていく必要があるわけです.部下のマネジメント法というのは,そこらの本屋にも結構置いてあるわけですけど,逆に自分の上司をマネジメントという観点でみるのは新鮮だなーと思って,GWの間に読んでみました*1.
")
Managing Your Boss (Harvard Business Review Classics)
- 作者: John J. Gabarro,John P. Kotter
- 出版社/メーカー: Harvard Business Review Press
- 発売日: 2008/01/08
- メディア: Kindle版
- この商品を含むブログを見る
ざっくりとしたレビュー
見出し的には以下のとおり.
- Misreading the boss-subordinate relationship
- Understanding the boss
- Understanding yourself
- Developing and managing the relationship
- Compatible work styles
- Mutual expectations
- A flow of information
- Dependability and honesty
- Good use of time and resources
この本を通しての一貫しているのは,上司と部下の関係は相互作用的な対人関係である,という社会心理学的な視点です*2.例えば成果を上げてのし上がってきた優秀なマネージャーが,気難しいボスとの関係がうまくいかず,結局事業が失敗してしまった場合に,気難しい上司にも問題はあるかもしれないが,このマネージャーは上司とうまく協調して物事を進めていくスキルが不足していた,という見方をします.とはいえ職場の力関係が示すように,基本的には部下が上司に対してどう付き合っていくかというのが,主要な観点になります.
Understanding the bossという見出しがあるように,まずは上司の性格,意思決定の仕方,ワークスタイルといった点を把握するところから始まります.その上で,上司がスムーズに業務をできるような形に自分のスタイルを調整して合わせていく,というのが基本的な流れです.そして面白いのは,これは功利的・政治的な問題というよりは*3,上司とうまく連携できることで,自分の仕事がうまく進められ,ひいては組織全体によい結果をもたらすという部分が強調されている点です.上司に媚びへつらうというよりも,自分の仕事をスムーズに進めるためには,そもそも上司と良好な関係を築けることが大事であるという話です*4.
もう少しだけ具体的な話でいうと,ワークスタイルを揃える(e.g. 文書で報告されるのが好きか,口頭が好きか),相互の期待を揃える(上司が何を期待しているかを把握する),情報の流し方を調整する(大事な問題だけを伝えるか,細かい情報も逐一伝えるか,ネガティブな情報を伝えるか)といった事柄が挙げられます.それ以外にも誠実であれ,とかどうでもいい話で上司の時間を浪費すると,本当に大事な案件に時間を割いてもらえない,とかそういった話が述べられています.
雑感
読んで思ったのは,これ自体は直属の上司との関係について書かれてはいるけど,組織内のキーパーソンとの関わり方全般について当てはまるよなぁ,ということです.組織にはいろいろな人がいるし,機能別組織であれば部署によって目指す目標は全く違うし,ある部署の目標と,3つ隣の部署の目標が正反対という場合だってあるわけです*5.なので複数の部署をまたいで物事を動かすには,相手の部署が何を目標としているか(何を期待しているか)を知った上で,自分のやりたいことが相手にとっても得になるように調整して,協調することが大事なわけです.これってまさにこの本で書かれていることですよね.
このことを敷衍していくと「情けは人のためならず」の心がけに行き着くかなーと思います.心理学的にはそれこそ古典のチャルディーニの「影響力の武器」なんかでも返報性の法則として書かれているように,こちらから何がしかの恩恵を施した場合,相手はどこかでそれをお返ししたくなるわけです.まぁ実際問題としては,そこまで打算的になってやるというより,一緒に仕事する相手が良い気持ちで仕事できる方が,自分も気分いいよねという単純な話でもいいかなと思ったりするわけですが.
![影響力の武器[第三版]: なぜ、人は動かされるのか](http://ecx.images-amazon.com/images/I/51cb7nbpZnL._SL160_.jpg "影響力の武器[第三版]: なぜ、人は動かされるのか")
- 作者: ロバート・B・チャルディーニ,社会行動研究会
- 出版社/メーカー: 誠信書房
- 発売日: 2014/07/10
- メディア: 単行本
- この商品を含むブログ (4件) を見る
あと,Harvard Business Review自体のまとめ記事がこちらにまとまっているので,合わせて読むとよいかなと思います.
ビッグデータの成熟期に改めて見直したいETL
Hadoopが出てきてから10年,ビッグデータという言葉が流行り始めてからでも5年以上が経ち,2016年現在では,Hadoopエコシステムを使ったデータ活用が当たり前のものとしてあります.とはいえ巷に出回っているビッグデータ活用事例というのは,綺麗な上澄みだけをすくい取っていたり,リリースしたてのピカピカのときに発表されていたり,というのが大半で,それが結構個人的に気に食わなかったりします.
ビッグデータが当たり前のものになっている現在においては,単に作っただけで価値があるというフェーズは過ぎ去っていて,継続的に運用しながら価値を生み出し続けることが,非常に重要な問題だと思います.特にビッグデータ界隈はミドルウェアやツールの陳腐化が激しく,またビジネス自体の変化速度も過去と比べてどんどん速くなっているわけで,そういった変化に対応していくためには,また別のスキルが必要とされるのではないでしょうか.このあたりについては,今年のHadoop conference JapanでされていたClouderaによるETLの概説,ドワンゴやDeNAの事例はまさにそういった問題を扱っています.みんな対外発表では綺麗なところを見せたいわけで,なかなかこうした実情が共有されることは少ないように感じています.
www.slideshare.net
www.slideshare.net
www.slideshare.net
でもこうした問題は,ビッグデータにより初めて起こったものではありません.データウェアハウス,ETLという言葉で,エンタープライズ業界では何十年も前から取り組まれており,ノウハウが積み上げられている分野でもあります*1.ビッグデータ活用自体がある程度成熟してきた今こそ,改めて長期的な運用を想定した,ETLの仕組み構築が注目されるべき時期に来ているのではないでしょうか*2.
データウェアハウスとETL
と,ちょっと挑発的な書き出しで始めましたが,要するに最近ラルフ・キンボールのThe Data Warehouse Toolkitを読んでいて,非常に感銘を受けたというお話です.このキンボール先生,スタースキーマで有名なディメンショナルモデル*3を提唱した人で,データウェアハウスの分野ではビル・インモンと並び最も有名な人の一人です.このThe Data Warehouse Toolkitは第3版まで出ていて,初版は日本語訳も出版されています*4.私は両方読んだんですが,第3版のほうがはるかに体系化されて,様々なノウハウが整理されているので,英語に苦がなければ原書で読むことをお勧めします.

The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling
- 作者: Ralph Kimball,Margy Ross
- 出版社/メーカー: Wiley
- 発売日: 2013/07/01
- メディア: ペーパーバック
- この商品を含むブログを見る

- 作者: ラルフキンボール,Ralph Kimball,藤本康秀,岡田和美,下平学,伊藤磨瑳也,小畑喜一
- 出版社/メーカー: 日経BP社
- 発売日: 1998/05/14
- メディア: 単行本
- 購入: 2人 クリック: 68回
- この商品を含むブログ (8件) を見る
さて,では具体的な話に進みたいと思います.まずディメンショナルモデルとは,スタースキーマとはなんぞや,というお話ですが,このあたりの概説については id:EulerDijkstra さんの以下の記事が非常にわかりやすいので,一読をお勧めします.
ぶっちゃけビッグデータ時代になっても,基本的なデータ設計というのはディメンショナルモデルから大きく外れるものではありません.よくあるウェブサイトのアクセスログベースのユーザアクセス動向の分析についても,生のhttpdログをHDFSに突っ込んで,それを加工してユーザアクセスファクトテーブルを作ります.次にユーザマスタ,商品マスタを業務系のDBからSqoopで吸い出してきて,適当に加工整形してユーザディメンション,商品ディメンションテーブルを作ります.あとは,Hiveクエリでも書いてユーザセグメント毎の商品購入動向を集計するわけです.簡単ですね.
長期的な運用を前提とした仕組みづくり
ビッグデータ活用,みたいなプロジェクトが立ち上がる際,うちの会社でもログ解析ができるようにしたい,そこから何か有用な知見が得られるんじゃないか,みたいなフワッとした要件で始まることって割とあると思うんですけれども,これって結構つらい話です.キンボール先生が本の中で再三繰り返しているのは,データウェアハウス構築においては,ビジネス側の要件が一番大事で,それを達成するための仕組みづくりをしなければいけない,ということです.Hadoopがいくらコモディティサーバ使えばいいっていっても,またクラウドを使えば簡単に構築できるっていっても,それなりのデータ量でそれなりの分析をしようと思ったら,すぐに結構な金額が吹っ飛んでいきますし,費用対効果を考えないで立ち上げると,間違いなく長期的にドツボにはまっていきます.また,誰も使わないデータウェアハウスを作り続けることほど,エンジニアとして悲しいこともないですしね.
そんなわけで,プロジェクトをうまく進めるためには,必ずエンジニアサイドだけでなく,ビジネスサイドのキーパーソンを巻き込んで進めましょう,という話になります.その上で,ビジネスサイドの人たちが分析しやすいラベルをつけたディメンションテーブルを構築し,入り組んだ集計処理はあらかじめ行ったビューを作っておく,といった配慮が求められます.というのは,ややこしい集計作業をビジネスサイドの人が毎回正しく実行してくれると期待するのは,基本的に間違っていて,もし複数人の集計結果が異なっていたとしたら,問い合わせがくる先はデータウェアハウスの開発マネージャーのところだからです.そして正しい数字を担保しないと,せっかくデータウェアハウスを作っても,結局誰も使ってくれなくなってしまいます.
また,あらゆる基準は時とともに変化することを前提として,あらかじめ設計しておかなければいけません.特にディメンションテーブルについて,時間の経過とともにカラムの内容がゆるやかに変化していきます.これをキンボール先生はSlowly Changeng Dimension (SCD) と呼んで,本の中でも繰り返しその対処法を説明しています.例えばECサービスにおけるユーザ情報なんかがその典型で,ユーザの登録住所や電話番号なんて情報は,そう頻繁に変わるわけではないですが,数年とかのスパンではそれなりの変更があると考えられます.これをキチッとトレースできるようにしておかないと,過去に遡った分析を行うことができなくなります.
本の中ではこの問題に対して以下のような基本の4種類の対応法を示しています*5.
1. 上書きする
基本的に変更がなく,過去の情報を参照する必要がないような場合には,単純に上書きしてしまいます.
2. 新しい行を加える
これがベーシックかつ一番よく用いられる方法で,値が変わった場合には,別の行を追加します.ディメンションにはあらかじめ追加日と失効日の2カラムを持っておき,値が変わった場合に,既存の行に失効日を追記することで,その行が有効な期間を特定できるようにします.また最新フラグを示すカラムを追加しておくことで,簡単に最新状態の行だけを絞り込むことができるようにしておくと便利です.
3. 新しい属性を加える
最新の値と,その1個前の値を比べたい場合に,この手法を使います.やり方は簡単で,現在の値カラムと,直前の値カラムの2つをあらかじめ用意しておき,値が変更された場合には,既存の行を書き換えて対応します.
4. ミニディメンションを用いる
これは頻繁に変更が起こる場合に用いられます.ディメンションテーブルは,マスタとしてファクトテーブルと結合されるので,あまりにこのデータサイズが大きいと,パフォーマンスに影響が出ます.そのような場合には,変化する頻度の高いカラムだけを抜き出して,それら全ての組合せを網羅したディメンションテーブルをあらかじめ用意しておきます.それとは別に,変化する頻度の低いカラムは,従来のディメンションテーブルにまとめておきます.変更頻度によりディメンションテーブルをあらかじめ分割しておくことで,保守性が高い仕組みが構築できます.
またこの場合の結合キーですが,キンボール先生は,何の意味もない連番の数字か,ランダムハッシュを用いることを強く推奨しています.例えば商品ディメンションで考えるなら,もともと商品IDがあるのが普通なので,これを結合キーに使ってしまえば良いと考えがちですが,これだと商品IDに何がしかの変更が加わった際に,一気に窮地に陥ります.この手のナチュラルキーは,直感的である一方,サービスの統合やID体系の見直しといった,長期間の運用でたまに起こるイベントへの耐久性が皆無に近いわけです*6.
これら以外にも,ETLで必要とされるコンポーネントを34に分類して,その概要を述べていたり,典型的なシステム構成や事例に基づいたデータスキーマ,またデータウェアハウス構築プロジェクトの進め方といった多様な観点について述べられています.本のメイン部分は,Hadoop以前の時代に書かれているため,特にパフォーマンス的な部分では古いなーという部分があります.ただそれって,従来であれば3ヶ月ぶんしか扱えなかったデータが3年分扱えるようになった*7とか,集計軸を削減していたのがしなくてよくなったとかいう程度の違いしかなくて,データサイズが増える段階のどこかで,同じ問題にぶち当たります.いくらHadoopがスケールアウトするといっても,会社の予算は有限なので,サーバを無尽蔵に増やせるわけはありません.費用対効果のトレードオフを考えて,できる限りチューニングを行う必要があることには変わりがありません.
また,Hadoopで非構造化した生データを,加工整形する前に扱うことができるという点についても,使い所は絞らないといけないです.システム関連系では,生のデータをストリーム処理したり,ミニバッチ的に処理したりで,うまく活用してレコメンドだのに活かしたり,というのはあり得る使い方ですけど,それはあくまでデータサーエンティストやデータマイニングエンジニアみたいな,一部の専門家たちに限定されるべきです.特にビジネスサイドの人たちが触るデータについては,時間をかけて加工整形して,元データの変更部分をETLで吸収する必要があることに変わりはないし,そうしないと正しいデータ活用,データに基づいた意思決定にはつながっていかないんじゃないかなーと思っています.
そんなこんなで,とりとめなくETLについて書いてきましたが,The Data Warehouse Toolkitはとても良い本なので,みなさん読みましょう,ということが言いたかっただけのエントリでした.
*1:ただエンタープライズのこうしたノウハウって,あんまり世の中にシェアされることがないようには思っています.まぁB2Bの受託開発がメインだと,なかなかノウハウをシェアするメリットもありませんからね...
*2:ちなみにこのあたり,Treasure Dataとかのマネージドなデータウェアハウスサービスを使っていれば構築運用部分の悩みは解消されるにせよ,どうやってデータを持つ点は使う側が考えなければいけない以上,決してETLが必要ないわけではないです.
*3:コメントで,ディメンジョンでなくディメンションでは,といただいたので,修正しました.その通りですね,お恥ずかしい...
*4:すでに絶版ですが,Amazonなんかで中古を買うことはできます.表紙の古臭さが,時代の流れを感じさせますね.
*5:ほんとうは,それらを組み合わせた手法が3つ紹介されており,合計7つだったりはします
*6:このあたり,私自身も実務で実感しています.
*7:つまり,3年以上のデータを扱おうと思った場合には,結局パフォーマンス的な問題が現れてくる
optim()で階層構造を持った多変数の最適化をしてみる
最適化周りの処理について実装する必要が出たので,optim() を調べて使ってみましたよ,という話.
optim() って関数の形で表わせさえすれば,結構なんでも自由にできるっぽくて便利です.特に,階層的な構造を持ったデータの最適化もできるのは大きいです.
例
階層化ということで,ここで例に挙げるのは,比率の最適化です.イメージとしては,各クラスにおける学級委員長の選出を思い浮かべてもらえればと思います.
各クラスには複数の立候補者がいて,その支持率が既知のものとします*1.各クラスの生徒に対して,支持している候補者と,目指すクラスの方向性についてのアンケート聞いたとしてください.その得られたアンケート結果に対しなにがしかの係数をかけて,各立候補者の支持スコアを算出します.で,それを全立候補者のスコア合計で割ってあげれば,各立候補者の支持率が擬似的に出せます.
そうすると,クラスごとに算出した支持率と,実際の支持率の両者が得られます.アンケート結果にかける係数を調整することで,支持率の予測と実際の乖離を0に近づけましょう,ということになります.この場合,係数がかかるのは各クラスの生徒ですが,知りたいのはクラスごとの支持率という,クラス単位のパラメタだという階層構造になるわけです.
サンプルデータの作成
とりあえず,以下のようにクラスデータを作っておきます.わかりやすくするために,クラスは2つ,各クラスの候補者も2人としておきます.ここでポイントは,予め各候補者のカラムを作っておくことです.各生徒の支持対象はわかっているので,ここでは1または0の値で表しちゃいます*2.
library(dplyr) # 選択肢1, 2のデータを作成して結合 # 項目は以下の通り # クラス番号 # 候補者1支持ダミー # 候補者2支持ダミー # 価値観1 # 価値観2 location1 <- matrix(c(rep(1, 100), rep(1, 30), rep(0, 70), rep(0, 30), rep(1, 70), rep(1, 71), rep(0, 29), rep(0.3, 69), rep(0.7, 31)), 100, 5) location2 <- matrix(c(rep(2, 100), rep(1, 50), rep(0,50), rep(0, 50), rep(1,50), rep(0.1, 40), rep(0.8, 20), rep(0.5, 40), rep(0.2, 20), rep(1, 80)), 100, 5) d <- as.data.frame(rbind(location1, location2)) colnames(d) <- c("class_id", "person1", "person2", "value1", "value2") # クラス1, 2の支持率データ # 項目は以下の通り # クラス番号 # 候補者1支持率 # 候補者2支持率 s <- as.data.frame(t(matrix(c(1, 0.8, 0.2, 2, 0.6, 0.4), 3, 2))) colnames(s) <- c("class_id", "support1", "support2") # 結合してデータセットを作成 ds <- d %>% inner_join(s, by="class_id")
最適化対象の関数の作成
やりたいのは各候補者のスコアを出して,それを既知の支持率と比較することです.まずはわかりやすくするために,1クラス分のデータだけでやってみたいと思います.
# 1クラスぶんにデータを絞る ds1 <- ds %>% filter(class_id==1) # 最適化する関数 predict_rating <- function(b, d, print=FALSE) { d_tmp <- d d_tmp$predict1 <- b[1]*d_tmp$person1*b[3]*d_tmp$value1*b[4]*d_tmp$value2 d_tmp$predict2 <- b[2]*d_tmp$person2*b[3]*d_tmp$value1*b[4]*d_tmp$value2 # クラスidでグループ化して合計スコアを出した上で,比率に変換する d_tmp2 <- d_tmp %>% group_by(class_id, support1, support2) %>% summarize(., predict1=sum(predict1), predict2=sum(predict2)) total <- d_tmp2$predict1+d_tmp2$predict2 d_tmp2$predict1 <- d_tmp2$predict1/total d_tmp2$predict2 <- d_tmp2$predict2/total if (print) { print(d_tmp2) } # 最少化する関数は二乗誤差 sum((d_tmp2$support1-d_tmp2$predict1)^2+abs(d_tmp2$support2-d_tmp2$predict2)^2) }
optim() で実行
ここまで用意ができたら,実際にoptim() で実行します.この場合,最適化したい係数は非負で一定の範囲の実数に抑えたいとします.そのような指定ができる手法は,どうやら "L-BFGS-B*3" だけらしいので,これを選択します.各変数は0から10の範囲を取るという制約を与えます*4.各係数の初期値には,平均と分散が1の正規分布から乱数を生成し,負の値は正にするかたちで用いています.
res <- optim(abs(rnorm(4, 1, 1)), predict_rating, d=ds1, method="L-BFGS-B", lower=0, upper=10, control=list(maxit=10000)) res
これを実行すると,以下のように結果が得られ,実際に最適化がなされていることが見て取れます.
> res <- optim(abs(rnorm(4, 1, 1)), + predict_rating, + d=ds1, + method="L-BFGS-B", + lower=0, + upper=10, + control=list(maxit=10000)) > res $par [1] 3.2007261 0.5497433 0.5569501 0.7339547 $value [1] 1.603087e-14 $counts function gradient 10 10 $convergence [1] 0 $message [1] "CONVERGENCE: REL_REDUCTION_OF_F <= FACTR*EPSMCH" > predict_rating(res$par, d=ds1, TRUE) Source: local data frame [1 x 5] Groups: class_id, support1 [?] class_id support1 support2 predict1 predict2 (dbl) (dbl) (dbl) (dbl) (dbl) 1 1 0.8 0.2 0.7999999 0.2000001 [1] 1.603087e-14
ここまで結果が得られたところで,最適化対象のクラス数を2にしてみましょう.ds1ではなくdsを使う,というだけですが.そうすると,見事に以下のように最適化された結果が得られています.もちろん2クラスに同じ係数を当てはめているため,クラス1については当てはまりが多少悪くなっています.それでもクラス1,2ともにそれなりによい当てはまりになっていることがわかるかと思います.
> res <- optim(abs(rnorm(4, 1, 1)), + predict_rating, + d=ds, + method="L-BFGS-B", + lower=0, + upper=10, + control=list(maxit=10000)) > res $par [1] 2.42237544 0.52544405 1.42063132 0.04326498 $value [1] 0.005155603 $counts function gradient 8 8 $convergence [1] 0 $message [1] "CONVERGENCE: REL_REDUCTION_OF_F <= FACTR*EPSMCH" > predict_rating(res$par, d=ds, TRUE) Source: local data frame [2 x 5] Groups: class_id, support1 [?] class_id support1 support2 predict1 predict2 (dbl) (dbl) (dbl) (dbl) (dbl) 1 1 0.8 0.2 0.7600352 0.2399648 2 2 0.6 0.4 0.6313148 0.3686852 [1] 0.005155603
glmnetで正則化を試してみる
タイトルの通り,よく考えたら今までL1/L2正則化を知識としては知ってるけど,実際に試したことはなかったことに気がついたので試してみましたよという話.L1/L2正則化にの理屈については,TJOさんのエントリとか,unnounnoさんのエントリとかをみてもらえれば良いのではと思います.それより詳しいことが知りたければ,PRMLでも読めば良いのではないでしょうか(適当*1).
まずはデータを眺める
使用したデータは,caretパッケージのcarsパッケージです*2.中古車販売のデータっぽくて,価格と,走行距離とか気筒とかドア数とかの車に関するカラムが並んでます.データを読み込んで,可視化して,とりあえず lm() してみます.
> library(glmnet) > library(caret) > library(psych) > > # load data > data(cars) > t(head(cars)) 1 2 3 4 5 6 Price 22661.05 21725.01 29142.71 30731.94 33358.77 30315.17 Mileage 20105.00 13457.00 31655.00 22479.00 17590.00 23635.00 Cylinder 6.00 6.00 4.00 4.00 4.00 4.00 Doors 4.00 2.00 2.00 2.00 2.00 2.00 Cruise 1.00 1.00 1.00 1.00 1.00 1.00 Sound 0.00 1.00 1.00 0.00 1.00 0.00 Leather 0.00 0.00 1.00 0.00 1.00 0.00 Buick 1.00 0.00 0.00 0.00 0.00 0.00 Cadillac 0.00 0.00 0.00 0.00 0.00 0.00 Chevy 0.00 1.00 0.00 0.00 0.00 0.00 Pontiac 0.00 0.00 0.00 0.00 0.00 0.00 Saab 0.00 0.00 1.00 1.00 1.00 1.00 Saturn 0.00 0.00 0.00 0.00 0.00 0.00 convertible 0.00 0.00 1.00 1.00 1.00 1.00 coupe 0.00 1.00 0.00 0.00 0.00 0.00 hatchback 0.00 0.00 0.00 0.00 0.00 0.00 sedan 1.00 0.00 0.00 0.00 0.00 0.00 wagon 0.00 0.00 0.00 0.00 0.00 0.00 > pairs.panels(cars) > > # lm > fit.lm <- glm(Price ~ ., data = cars) > summary(fit.lm) Call: glm(formula = Price ~ ., data = cars) Deviance Residuals: Min 1Q Median 3Q Max -9513.5 -1540.9 125.4 1470.3 13619.7 Coefficients: (3 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) -1.124e+03 9.926e+02 -1.133 0.25773 Mileage -1.842e-01 1.256e-02 -14.664 < 2e-16 *** Cylinder 3.659e+03 1.133e+02 32.286 < 2e-16 *** Doors 1.567e+03 2.589e+02 6.052 2.2e-09 *** Cruise 3.409e+02 2.960e+02 1.152 0.24978 Sound 4.409e+02 2.345e+02 1.880 0.06043 . Leather 7.908e+02 2.497e+02 3.167 0.00160 ** Buick 9.477e+02 5.525e+02 1.715 0.08670 . Cadillac 1.336e+04 6.248e+02 21.386 < 2e-16 *** Chevy -5.492e+02 4.397e+02 -1.249 0.21203 Pontiac -1.400e+03 4.868e+02 -2.875 0.00414 ** Saab 1.228e+04 5.546e+02 22.139 < 2e-16 *** Saturn NA NA NA NA convertible 1.102e+04 5.419e+02 20.340 < 2e-16 *** coupe NA NA NA NA hatchback -6.362e+03 6.104e+02 -10.422 < 2e-16 *** sedan -4.449e+03 4.463e+02 -9.969 < 2e-16 *** wagon NA NA NA NA --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for gaussian family taken to be 8445957) Null deviance: 7.8461e+10 on 803 degrees of freedom Residual deviance: 6.6639e+09 on 789 degrees of freedom AIC: 15122 Number of Fisher Scoring iterations: 2
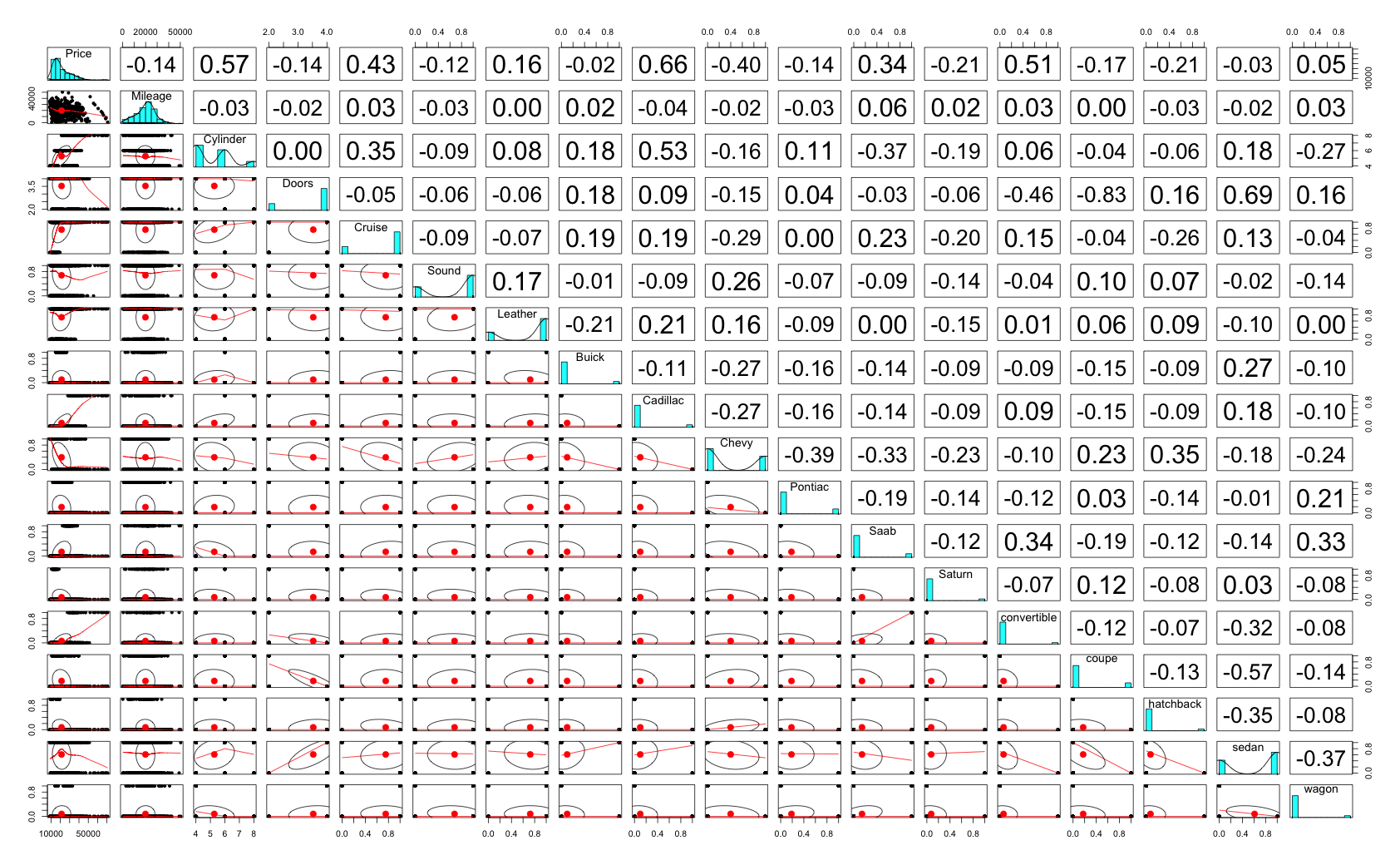
相関は各変数そこそこある感じで,極端に高いものはないみたいです.でもlm()の結果をみると,Saturnとcoupeとwagonは落ちちゃってますね.まぁその辺りは気にせず次へ.
glmnetでL1正則化
Rで正則化をするパッケージとして {glmnet} を使います.読み込みにfactor型は使えず,すべて数値型で渡す必要があります.かつYとXは別のmatrixとして渡してあげる必要があるとのこと.実行して,plotしてみます.式中の alpha が1ならL1正則化で,0ならL2正則化になります.そしてその間ならElastic Netです.
> pairs.panels(cars) > # lasso > fit.glmnet.lasso <- glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + alpha = 1) > plot(fit.glmnet.lasso)

この図は,左にいくほどL1正則化が強く効いている状態とのことです.さらに cv.glmnet() で5 foldのクロスバリデーションを行います.
> fit.glmnet.lasso.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 1) > plot(fit.glmnet.lasso.cv) > fit.glmnet.lasso.cv$lambda.min [1] 18.54925 > fit.glmnet.lasso.cv$lambda.1se [1] 275.4505 > coef(fit.glmnet.lasso.cv, s = fit.glmnet.lasso.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 3332.5402054 Mileage -0.1816504 Cylinder 3634.6147087 Doors -628.9022241 Cruise 340.6710317 Sound 382.0774957 Leather 753.7844280 Buick 924.8954890 Cadillac 13401.5393074 Chevy -482.8713605 Pontiac -1294.4163546 Saab 12273.6389734 Saturn . convertible 11016.0739756 coupe . hatchback -1881.6575830 sedan . wagon 4317.2107830

MSE*3が最小になる lambda の値が18.55です.上の図において,log(lambda) = 3 あたりに点線が縦に引かれていますが,これがminの位置になります.で,真ん中ぐらいにある点線が,lambdaの1se地点の値です.lm() の結果と,lambda.minにおける各係数のあたいをみてみると,微妙に違いがありますね.lassoの場合はwagonではなくsedanが係数0に収束しているようです.
ちなみに,coef() を実行したときにオプションで指定している s というのは,coef を表示する際の lambda の値を指します. cranのドキュメントには,p18の predict.cv.glmnet に
Value(s) of the penalty parameter lambda at which predictions are required. Default
is the value s="lambda.1se" stored on the CV object. Alternatively
s="lambda.min" can be used. If s is numeric, it is taken as the value(s) of
lambda to be used.
と記述されています.
L2正則化
同じように,今度は alpha を0にして,ridge回帰をおこなってみます.
> # ridge > fit.glmnet.ridge <- glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + alpha = 0) > plot(fit.glmnet.ridge) > ## cv > fit.glmnet.ridge.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 0) > plot(fit.glmnet.ridge.cv) > fit.glmnet.ridge.cv$lambda.min [1] 714.8007 > fit.glmnet.ridge.cv$lambda.1se [1] 1370.924 > coef(fit.glmnet.ridge.cv, s = fit.glmnet.ridge.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 10337.0169783 Mileage -0.1712252 Cylinder 3170.1294044 Doors -831.5817913 Cruise 1026.4850774 Sound 224.6847147 Leather 956.7665236 Buick -1936.7129470 Cadillac 10320.3212670 Chevy -3629.5572140 Pontiac -4111.5436304 Saab 7869.4887792 Saturn -3239.5070500 convertible 9384.0693961 coupe -1729.7150676 hatchback -2962.1017215 sedan -1250.9639471 wagon 2760.2080200
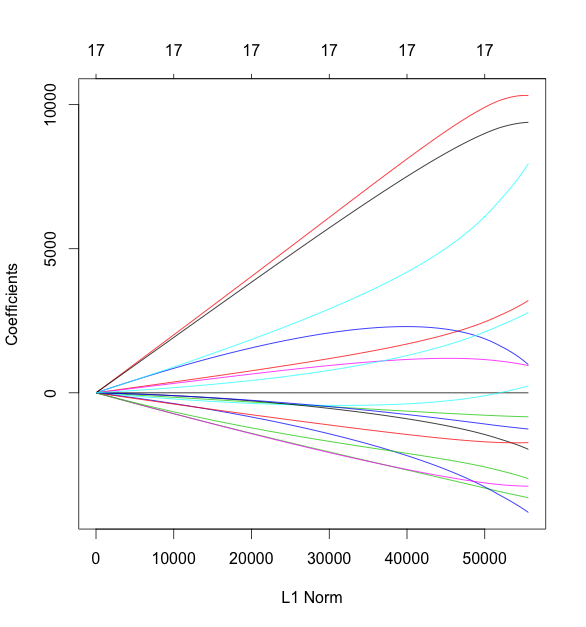
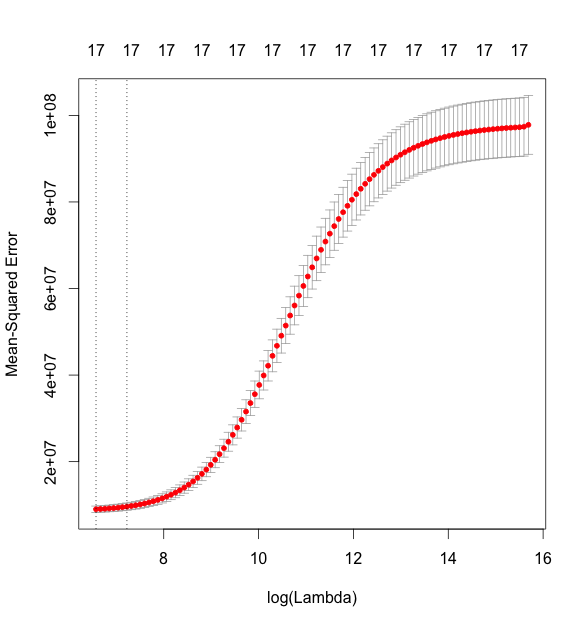
lassoのときとは結果が大きく変わりました.
ElasticNetによる正則化
最後に,ElasticNetを試してみます.基本的には,0 < alpha < 1 であればよいのですが,この alpha の値を決める方法は,{glmnet} 内では提供されていません*4ので,今回はえいやで alpha=0.5 にしちゃいます.ちゃんとやりたいのであれば,{caret} あたりを使って,lambda とalpha を共に変動させてみるのがよいかと思います.
> fit.glmnet.elasticnet.cv <- cv.glmnet(as.matrix(cars[, -1]), + as.matrix(cars[, 1]), + nfold = 5, + alpha = 0.5) > plot(fit.glmnet.elasticnet.cv) > fit.glmnet.elasticnet.cv$lambda.min [1] 33.80277 > fit.glmnet.elasticnet.cv$lambda.1se [1] 416.7364 > coef(fit.glmnet.elasticnet.cv, s = fit.glmnet.elasticnet.cv$lambda.min) 18 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 3864.0228103 Mileage -0.1815926 Cylinder 3625.4650658 Doors -626.2371069 Cruise 371.2344641 Sound 386.8548536 Leather 767.8711841 Buick 402.2514994 Cadillac 12865.1630823 Chevy -1013.4253903 Pontiac -1821.5463454 Saab 11707.2380808 Saturn -464.8502014 convertible 11028.5218995 coupe . hatchback -1877.0655854 sedan -3.3327249 wagon 4323.9610872
ということで,{glmnet} でL1/L2正則化を試してみました.なお,コードはgistにあげてあるので,興味がある方はどうぞ.
*1:単に「正則化 amazon」で検索したら一番上に出てきたのがビショップ本だっただけです.
*2:MiluHatsuneさんのエントリがわかりやすかったので,それをベースになぞってる感じです.
*3:Mean Squared Error,つまり予測値と実際の値の差の二乗和を意味します.
*4:cross validation - Choosing optimal alpha in elastic net logistic regression - Cross Validated
RStudio Serverの更新とロケール設定
RStudio Serverを久しぶりに使おうと思ってアクセスしたら,なんかバージョンが古すぎてggplot2もdplyrもtidyrも入れられない有様だったので,アップデートをしましたよの備忘録.元バージョンはR3.1.0にRStudio0.97あたり.OSはCentOS6.5でした.
Rについては,cranから最新版を落としてmakeしてinstallすればOK.コンパイルの際には enable-R-shlib をつけないとダメとのこと*1.ちなみにyumから入れると3.1.0だったので,基本的にソースからビルドせざるをえない感じです.
$ cd /tmp $ wget wget https://cran.r-project.org/src/base/R-3/R-3.2.3.tar.gz $ tar xvf R-3.2.3.tar.gz $ cd R-3.2.3 $ ./configure --with-readline=no --with-x=no --enable-R-shlib $ make $ sudo make install
続いてRStudio Serverのインストール.こっちはrpmを公式から落としてきて,yumで入れればOK.
$ wget https://download2.rstudio.org/rstudio-server-rhel-0.99.879-x86_64.rpm $ sudo yum install --nogpgcheck rstudio-server-rhel-0.99.879-x86_64.rpm
で,このあと `sudo rstudio-server restart` したら,なんか以下のようなエラーがでてうまく動いてくれない.localeコマンドでわかる通り,これはOSのロケールが適切に設定されていないときに出るエラーとのこと.
$ sudo rstudio-server restart 16 Feb 2016 07:25:10 [rserver] ERROR Unexpected exception: locale::facet::_S_create_c_locale name not valid; LOGGED FROM: int main(int, char* const*) /root/rstudio/src/cpp/server/ServerMain.cpp:547 /usr/sbin/rstudio-server: line 33: return: can only `return' from a function or sourced script rstudio-server start/running, process 4032 $ locale locale: Cannot set LC_CTYPE to default locale: No such file or directory locale: LC_ALL?????????????????????: ?????????????????????? ...
この場合,LC_CTYPEを設定してあげて,再起動すればOK.このあたりの変数の意味は,このあたりを参照してください.
$ sudo vim /etc/sysconfig/i18n LANG="en_US.UTF-8" LC_CTYPE="ja_JP.UTF-8" # この行を追加 SYSFONT="latarcyrheb-sun16" $ sudo reboot
これで無事アクセスできました.
*1:shlibっていうのはshared libraryのことらしいです
データビジネスに関して2015年に読んだ本
気がつけば2015年も大晦日で,早い一年でした.ということで,恒例の今年読んだ本紹介をしておきたいと思います.ちなみに昨年と一昨年のはこちら.各セグメント毎に,個人的に参考になった順,面白かった順に並べています.マーケティングとマネジメントが前面に出ているのが,普段のお仕事で担当しているのがそっちメインだから,というだけで他意はないです.
smrmkt.hatenablog.jp
smrmkt.hatenablog.jp
マーケティング
USJのジェットコースターはなぜ後ろ向きに走ったのか?

- 作者: 森岡毅
- 出版社/メーカー: KADOKAWA/角川書店
- 発売日: 2014/02/26
- メディア: 単行本
- この商品を含むブログ (3件) を見る
こころを動かすマーケティング

こころを動かすマーケティング―コカ・コーラのブランド価値はこうしてつくられる
- 作者: 魚谷雅彦
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2009/08/07
- メディア: 単行本
- 購入: 4人 クリック: 41回
- この商品を含むブログ (23件) を見る
売れるもマーケ 当たるもマーケ

- 作者: アルライズ,ジャックトラウト,Al Ries,Jack Trout,新井喜美夫
- 出版社/メーカー: 東急エージェンシー出版部
- 発売日: 1994/01
- メディア: 単行本
- 購入: 17人 クリック: 250回
- この商品を含むブログ (61件) を見る
ラストワンマイル

- 作者: 楡周平
- 出版社/メーカー: 新潮社
- 発売日: 2006/10/26
- メディア: 単行本
- クリック: 4回
- この商品を含むブログ (15件) を見る
スマホに満足してますか
")
スマホに満足してますか? ユーザインタフェースの心理学 (光文社新書)
- 作者: 増井俊之
- 出版社/メーカー: 光文社
- 発売日: 2015/02/17
- メディア: 新書
- この商品を含むブログ (8件) を見る
マネジメント
ピクサー流 創造するちから

ピクサー流 創造するちから―小さな可能性から、大きな価値を生み出す方法
- 作者: エド・キャットムル著,エイミー・ワラス著,石原薫訳
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2014/10/03
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (9件) を見る
ワークルールズ

- 作者: ラズロ・ボック,鬼澤 忍,矢羽野 薫
- 出版社/メーカー: 東洋経済新報社
- 発売日: 2015/07/31
- メディア: 単行本
- この商品を含むブログ (5件) を見る
巨像も踊る

- 作者: ルイス・V・ガースナー,山岡洋一,高遠裕子
- 出版社/メーカー: 日本経済新聞社
- 発売日: 2002/12/02
- メディア: 単行本
- 購入: 22人 クリック: 313回
- この商品を含むブログ (94件) を見る
経営パワーの危機
")
経営パワーの危機―会社再建の企業変革ドラマ (日経ビジネス人文庫)
- 作者: 三枝匡
- 出版社/メーカー: 日本経済新聞社
- 発売日: 2003/03
- メディア: 文庫
- 購入: 21人 クリック: 99回
- この商品を含むブログ (51件) を見る
リスク確率に基づくプロジェクト・マネジメントの研究

リスク確率に基づくプロジェクト・マネジメントの研究【知の偉産シリーズ】 理工00005
- 作者: 佐藤知一
- 出版社/メーカー: 静岡学術出版
- 発売日: 2013/02/01
- メディア: DVD-ROM
- この商品を含むブログを見る
brevis.exblog.jp
統計学・機械学習
オンライン機械学習
")
- 作者: 海野裕也,岡野原大輔,得居誠也,徳永拓之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
smrmkt.hatenablog.jp
smrmkt.hatenablog.jp
深層学習
")
- 作者: 岡谷貴之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (6件) を見る
基礎からのベイズ統計学

基礎からのベイズ統計学: ハミルトニアンモンテカルロ法による実践的入門
- 作者: 豊田秀樹
- 出版社/メーカー: 朝倉書店
- 発売日: 2015/06/25
- メディア: 単行本
- この商品を含むブログ (4件) を見る
岩波データサイエンス

- 作者: 岩波データサイエンス刊行委員会
- 出版社/メーカー: 岩波書店
- 発売日: 2015/10/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (6件) を見る
データ分析プロセス
")
- 作者: 福島真太朗,金明哲
- 出版社/メーカー: 共立出版
- 発売日: 2015/06/25
- メディア: 単行本
- この商品を含むブログ (2件) を見る
組み合わせ最適化とアルゴリズム
")
組合せ最適化とアルゴリズム (インターネット時代の数学シリーズ 8)
- 作者: 久保幹雄,戸川隼人,杉原厚吉,中嶋正之,野寺隆志
- 出版社/メーカー: 共立出版
- 発売日: 2000/12/10
- メディア: 単行本
- 購入: 3人 クリック: 57回
- この商品を含むブログ (7件) を見る
集合知プログラミング

- 作者: Toby Segaran,當山仁健,鴨澤眞夫
- 出版社/メーカー: オライリージャパン
- 発売日: 2008/07/25
- メディア: 大型本
- 購入: 91人 クリック: 2,220回
- この商品を含むブログ (276件) を見る
ベイズ統計と統計物理

- 作者: 伊庭幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2003/08/27
- メディア: 単行本
- 購入: 13人 クリック: 151回
- この商品を含むブログ (41件) を見る
はじめてのパターン認識

- 作者: 平井有三
- 出版社/メーカー: 森北出版
- 発売日: 2012/07/31
- メディア: 単行本(ソフトカバー)
- 購入: 1人 クリック: 7回
- この商品を含むブログ (3件) を見る
入門オペレーションズリサーチ

- 作者: 松井泰子,根本俊男,宇野 毅明
- 出版社/メーカー: 東海大学出版会
- 発売日: 2008/03
- メディア: 単行本
- 購入: 1人 クリック: 56回
- この商品を含むブログ (4件) を見る
エンジニアリング
コンピュータ・アーキテクチャ技術入門
")
コンピュータアーキテクチャ技術入門 ~高速化の追求×消費電力の壁 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2014/05/01
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
")
プロセッサを支える技術 ??果てしなくスピードを追求する世界 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2011/01/06
- メディア: 単行本(ソフトカバー)
- 購入: 22人 クリック: 250回
- この商品を含むブログ (54件) を見る
計算機に関わるハードウェア全般の概説書.何年か前に,同じHisa Andoさんのプロセッサを支える技術を読みましたけど,これのさらに拡張版といった趣きの本.富豪的プログラミングができる場合も多々ある現在では,コードを書く際に実行環境の方には割と無頓着でもそんなに問題はないのですが,場合によってはかなり気を使わないといけないことも結構あります.特にAPIのレイテンシを気にしないといけない場合とか,大規模行列演算をやるとか,Hadoop使うとかみたいな場合には,ソフトウェア実装の前提なるハードウェア構成を考えていないとうまく機能しないです.そのあたりを(結構記述は込み入っていて理解するのは時間がかかりますが,それでも他に類書がないくらいに)わかりやすく説明している,とても良い本だと思います.
理論から学ぶ実践データベース入門
")
理論から学ぶデータベース実践入門 ~リレーショナルモデルによる効率的なSQL (WEB+DB PRESS plus)
- 作者: 奥野幹也
- 出版社/メーカー: 技術評論社
- 発売日: 2015/03/10
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (13件) を見る
SQL実践入門
")
SQL実践入門──高速でわかりやすいクエリの書き方 (WEB+DB PRESS plus)
- 作者: ミック
- 出版社/メーカー: 技術評論社
- 発売日: 2015/04/11
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
データ匿名化手法

- 作者: Khaled El Emam,Luk Arbuckle,木村映善,魔狸,笹井崇司
- 出版社/メーカー: オライリージャパン
- 発売日: 2015/05/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
熊とワルツを

- 作者: トム・デマルコ,ティモシー・リスター,伊豆原弓
- 出版社/メーカー: 日経BP社
- 発売日: 2003/12/23
- メディア: 単行本
- 購入: 7人 クリック: 110回
- この商品を含むブログ (150件) を見る
プログラミングHive

- 作者: Edward Capriolo,Dean Wampler,Jason Rutherglen,佐藤直生,嶋内翔,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/06/15
- メディア: 大型本
- この商品を含むブログ (3件) を見る
初めてのSpark

- 作者: Holden Karau,Andy Konwinski,Patrick Wendell,Matei Zaharia,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2015/08/22
- メディア: 大型本
- この商品を含むブログ (3件) を見る
HBase徹底入門

HBase徹底入門 Hadoopクラスタによる高速データベースの実現
- 作者: 株式会社サイバーエージェント鈴木俊裕,梅田永介,柿島大貴
- 出版社/メーカー: 翔泳社
- 発売日: 2015/01/28
- メディア: 大型本
- この商品を含むブログ (1件) を見る
smrmkt.hatenablog.jp
サーバ/インフラエンジニア養成読本 管理/監視編
![【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)](http://ecx.images-amazon.com/images/I/51UVepGMSfL._SL160_.jpg "【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)")
【改訂新版】 サーバ/インフラエンジニア養成読本 管理/監視編 [24時間365日稼働を支える知恵と知識が満載!] (Software Design plus)
- 作者: 養成読本編集部
- 出版社/メーカー: 技術評論社
- 発売日: 2014/04/11
- メディア: 大型本
- この商品を含むブログ (3件) を見る
Webエンジニアが知っておきたいインフラの基本

- 作者: 馬場俊彰(ハートビーツ)
- 出版社/メーカー: マイナビ出版
- 発売日: 2014/12/27
- メディア: Kindle版
- この商品を含むブログを見る
システムはなぜダウンするのか

- 作者: 大和田尚孝,日経コンピュータ
- 出版社/メーカー: 日経BP社
- 発売日: 2009/01/22
- メディア: 単行本
- 購入: 24人 クリック: 345回
- この商品を含むブログ (45件) を見る
IT投資の評価手法

- 作者: 大和田崇
- 出版社/メーカー: 中央経済社
- 発売日: 2007/03
- メディア: 単行本
- 購入: 1人 クリック: 8回
- この商品を含むブログ (4件) を見る
徹底解説! プロジェクトマネジメント

- 作者: 岡村正司
- 出版社/メーカー: 日経BP社
- 発売日: 2003/06/28
- メディア: 単行本
- 購入: 1人 クリック: 6回
- この商品を含むブログ (6件) を見る
その他
トップレフト

- 作者: 黒木亮
- 出版社/メーカー: サウンズグッド カンパニー
- 発売日: 2014/04/25
- メディア: Kindle版
- この商品を含むブログを見る
要するに
")
- 作者: 山形浩生
- 出版社/メーカー: 河出書房新社
- 発売日: 2008/02/04
- メディア: 文庫
- 購入: 9人 クリック: 145回
- この商品を含むブログ (57件) を見る