中古マンション売買データを分析してみた(2) - 路線と駅による中古売買価格の違い
というわけで前回予告した通りに,引き続き川崎横浜の中古住宅についてみていきましょう.今回のテーマは路線と駅,です.その中でも個人的な興味は,特に東横線プレミアムってやつは存在するのか,というものです*1.実際,東横線沿いの住宅ショールームとかみにいくと,立地や都心アクセスがそこまでずば抜けてるわけでもないのに,やたらに値段の高い物件とかあるわけです.そういうときに営業さんに高いっすねーというと,大概「東横線ですから」とか「万が一中古で手放すときでも値下がりしないですよ」とか言い放ってくるパターンがそれなりにあります.まぁそんなわけで,今回は路線と駅によるブランド力を検証したいと思います.
モデル
仮説を検証するためのモデルについてですが,今回は路線と駅を使って線形モデルを組み立てます.データに含まれる路線と駅は,それぞれ23路線,133駅と結構な数があるため,これをそのまま通常の回帰モデルに突っ込むのはいかにも分が悪い*2.そんなわけでMCMC使って,路線と駅を一気に突っ込んでパラメタ推定をやってしまうことにします.ちなみに,既にいくつも優れた解説があるのでMCMCの説明とかはしません.書籍で読むなら「みどりぼん」で有名な久保先生の本が,とても良書なので読むことをお勧めします.
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
- 購入: 16人 クリック: 163回
- この商品を含むブログ (19件) を見る
モデルとしては,以下の形にしました.極めてシンプルに,路線と駅から平米単価を予測するモデルです*3.今回はRからJAGSをキックしているので,以下のようなBUGSコードを用いました.路線と駅をモデルに組み込み,かつ路線と駅については正規分布を事前分布に設定しています.また従属変数の平米単価も正規分布で当てはめています*4.詳細なコードはエントリの最後にまとめています*5.
mantion_model <- function() { # main model for (i in 1:N) { PRICE[i] ~ dnorm(b+bS[STATION[i]]+bT[TRAIN[i]], tau[1]) } # prior distribution b ~ dnorm(0.0, 1.0e-6) for (i in 1:N.station) { bS[i] ~ dnorm(0.0, tau[2]) } for (i in 1:N.train) { bT[i] ~ dnorm(0.0, tau[3]) } for (i in 1:N.tau) { tau[i] <- 1 / (sigma[i] * sigma[i]) sigma[i] ~ dunif(0.0, 1.0e+6) } }
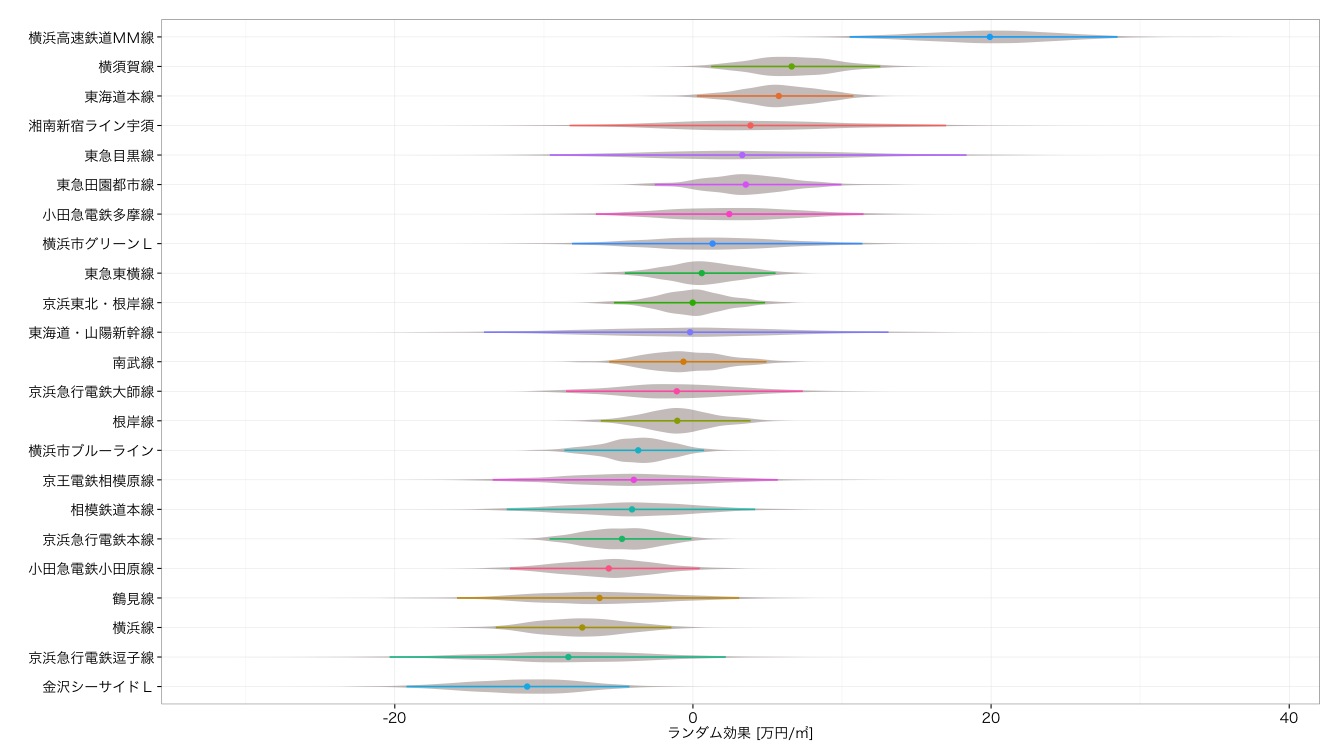
路線毎の単価
早速ですが結果にいっちゃいます.結果としては,みなとみらい線(図中の「横浜高速鉄道MM線」*6)が圧勝でした.よくよく考えたら,みなとみらい線はたった6駅しかなく,かつその6駅はすべて横浜中心部の主要ポイントを占めているわけですから,当たり前の結果といえます.そしてその次は横須賀線,東海道本線と意外な結果です*7.気になる東横線は上から9番目と,実際のところは高くも低くもないようです.
逆に価格の低いのは,金沢シーサイドラインと京浜急行電鉄逗子線で,神奈川の大分南の方ですし,今回の集計対象の中では一番都心から遠い路線なので,この結果も妥当といえるかと思います.その上には鶴見線,横浜線とこれもまた納得のランクインですね.
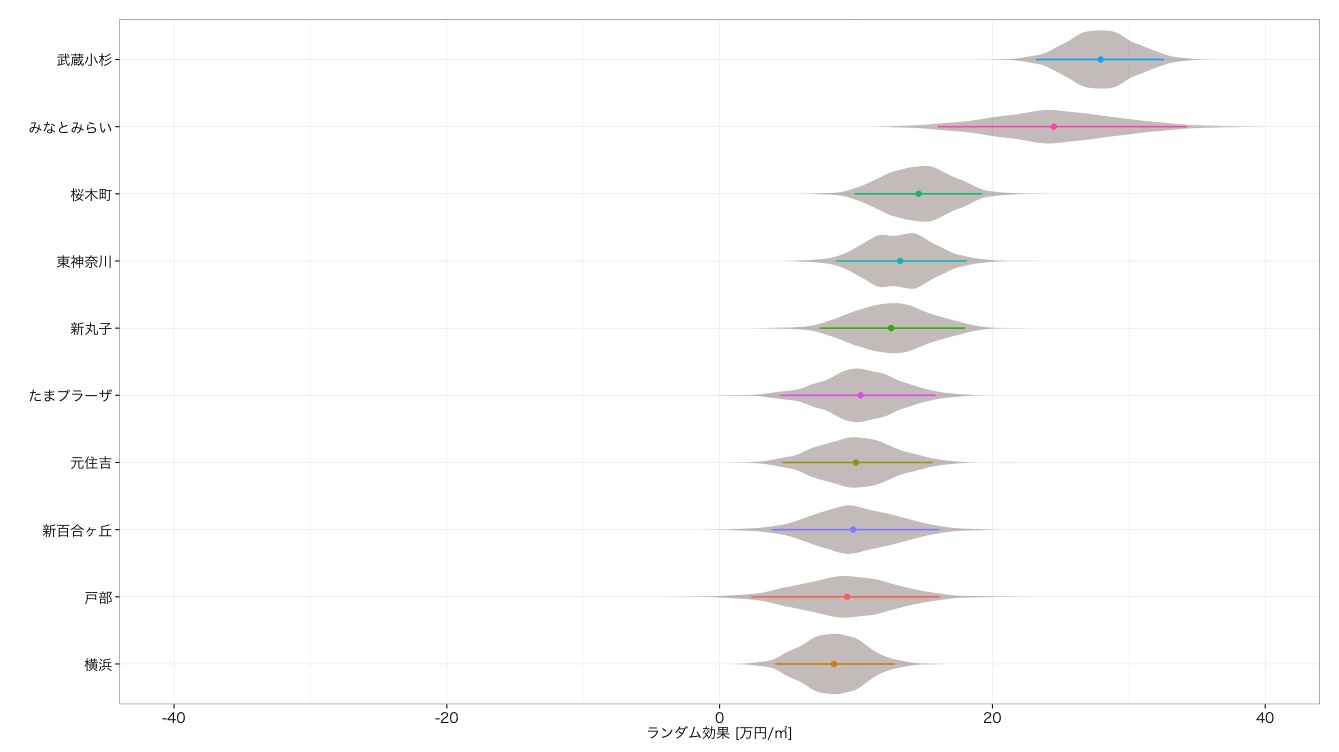
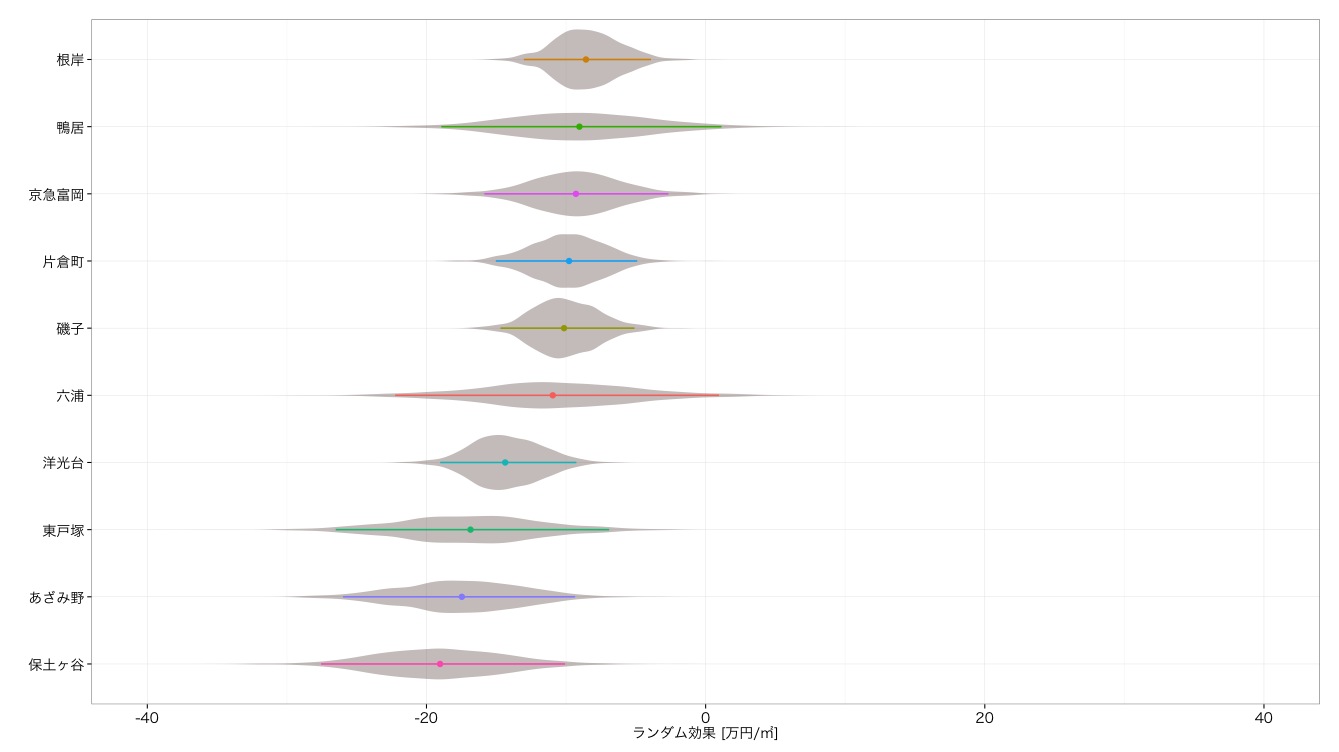
駅毎の単価
路線の次は駅にいきたいと思います.こちらは数が多すぎるので,すべてを紹介するのは差し控えてトップ10とワースト10をご紹介したいと思います.
問題
さて,ここまで結果をだーっとお見せしましたが,このモデルにはまだ大きな問題があります.それは駅からの距離と築年数をモデルに入れていない点です.先ほど書いたように,あざみ野が低いランクになってしまったのは,おそらくこれが原因ではないかと思われます.あざみ野は車で生活することが前提の高級住宅地であるため,そもそも今回扱っている中古マンションデータではそもそも余り高い評価はされにくい地域だといえます.それよりも高級住宅地にありがちな,車で生活することが前提の商圏により,徒歩分数が長い物件が多い,また比較的古めの地域であるため築年数が古い物件が多い,といったことが低価格の理由だと思われます*8.
で,それならモデルに両変数を組み込めばいいじゃないか,という話なのですが,駅からの距離と築年数をモデルに組み込むと,まともな値がかえってこない状態になってしまっています.特に築年数に関しては,平米単価との単相関が0.7以上あるにも関わらず,前回の記事でお見せしたように,1990年代以降に傾きが大きくあがり,実は非線形の関係にあります.このあたりをうまくモデルに組み込まないと,まともな推定違えられないように考えています.なので引き続きこのあたりを再検討したいところです.
とりあえず,上記の問題点に関しては,後日別エントリでまとめたいと思います.おそらくは純粋にテクニカルな内容になってしまうので,読み物としては特に面白くも何ともないと思いますが...
ということで,今回はこの辺で.
コード
# load library library('ggplot2') library('rjags') library('R2WinBUGS') library('dplyr') # load data d <- read.delim('data/mantions.csv', header=T, sep=',') d <- na.omit(d) # mcmc modeling ## model description mantion_model <- function() { # main model for (i in 1:N) { PRICE[i] ~ dnorm(b+bS[STATION[i]]+bT[TRAIN[i]], tau[1]) } # prior distribution b ~ dnorm(0.0, 1.0e-6) for (i in 1:N.station) { bS[i] ~ dnorm(0.0, tau[2]) } for (i in 1:N.train) { bT[i] ~ dnorm(0.0, tau[3]) } for (i in 1:N.tau) { tau[i] <- 1 / (sigma[i] * sigma[i]) sigma[i] ~ dunif(0.0, 1.0e+6) } } # write out model file.bugs <- file.path('script/mantion.bug') R2WinBUGS::write.model(mantion_model, file.bugs) # data for JAGS list.data <- list( PRICE = d$price, TRAIN = d$train, STATION = d$station, N = nrow(d), N.train = length(unique(d$train)), N.station = length(unique(d$station)), N.tau = 3 ) # initial value for JAGS inits <- list( b = rnorm(1, 39.22, 16.88), bS = rnorm(length(unique(d$station)), 0, 100), bT = rnorm(length(unique(d$train)), 0, 100), sigma = runif(3, 0, 100) ) # estimate parameters params <- c('b', 'bS', 'bT', 'sigma') # model definition model <- jags.model( file = file.bugs, data = list.data, inits = list(inits, inits, inits), n.chain = 3 ) # set MCMC burn-in cycles update(model, 100) # conduct MCMC silumation results post.list <- coda.samples( model, params, thin = 3, n.iter = 1500 ) summary(post.list) # graph plot(post.list) # visualize param by train n.samples <- niter(post.list) * nchain(post.list) pos.bT1 <- match('bT[1]', varnames(post.list)) range.bT <- pos.bT1:(pos.bT1 + max(d$train) - 1) train_name = c('湘南新宿ライン宇須', '東海道本線', '南武線', '鶴見線', '横浜線', '根岸線', '横須賀線', '京浜東北・根岸線', '東急東横線', '京浜急行電鉄本線', '京浜急行電鉄逗子線', '相模鉄道本線', '横浜市ブルーライン', '金沢シーサイドL', '横浜高速鉄道MM線', '横浜市グリーンL', '東海道・山陽新幹線', '東急目黒線', '東急田園都市線', '京王電鉄相模原線', '小田急電鉄多摩線', '京浜急行電鉄大師線', '小田急電鉄小田原線') bT <- data.frame(value = c(sapply(range.bT, function(i) unlist(post.list[, i]))), train = factor(rep(train_name, each = n.samples), level=train_name), ymax=rep(0, n.samples), ymin=rep(0, n.samples)) bT.qua <- ddply(bT, .(train), summarize, median=median(value), ymax=quantile(value, prob=0.975), ymin=quantile(value, prob=0.025)) colnames(bT.qua)[2] <- "value" p <- ggplot(bT, aes(x=reorder(train, value), y=value, group=train, color=train, ymax=ymax, ymin=ymin)) p <- p + geom_violin(trim=F, fill="#5B423D", linetype="blank", alpha=I(1/3)) p <- p + geom_pointrange(data=bT.qua, size=0.75) p <- p + coord_flip() p <- p + labs(x="", y="ランダム効果 [万円/㎡]") p <- p + theme_bw(base_family = "HiraKakuProN-W3") p <- p + theme(axis.text.x=element_text(size=14), axis.title.x=element_text(size=14), axis.text.y=element_text(size=14), legend.position="none") plot(p) # visualize param by station n.samples <- niter(post.list) * nchain(post.list) pos.bS1 <- match('bS[1]', varnames(post.list)) range.bS <- pos.bS1:(pos.bS1 + max(d$station) - 1) station_name = c('久地', '六浦', '反町', '大口', '子安', '小机', '尻手', '山手', '川崎', '平間', '幸浦', '戸部', '新羽', '日吉', '杉田', '柿生', '栗平', '根岸', '横浜', '浅野', '港町', '生田', '生麦', '登戸', '白楽', '矢向', '磯子', '綱島', '菊名', '蒔田', '追浜', '関内', '高津', '高田', '鳥浜', '鴨居', '鶴川', '鶴見', '鷺沼', '上大岡', '上星川', '上永谷', '下永谷', '並木北', '中野島', '五月台', '元住吉', '八丁畷', '八景島', '南太田', '吉野町', '向河原', '大倉山', '天王町', '妙蓮寺', '宮前平', '宮崎台', '宿河原', '屏風浦', '平沼橋', '弘明寺', '新丸子', '新子安', '新川崎', '新杉田', '新横浜', '東戸塚', '東白楽', '東門前', '桜木町', '梶が谷', '洋光台', '津田山', '浜川崎', '港南台', '溝の口', '片倉町', '矢野口', '石川町', '神奈川', '稲田堤', '能見台', '若葉台', '西横浜', '鈴木町', '阪東橋', '馬車道', '高島町', '鹿島田', '黄金町', 'あざみ野', 'はるひ野', '並木中央', '二子新地', '井土ヶ谷', '京急富岡', '京急川崎', '京急鶴見', '保土ヶ谷', '北新横浜', '南部市場', '小島新田', '岸根公園', '川崎大師', '日ノ出町', '日吉本町', '東神奈川', '武蔵中原', '武蔵小杉', '武蔵新城', '港南中央', '産業道路', '百合ヶ丘', '花月園前', '金沢八景', '金沢文庫', '鶴見小野', '鶴見市場', '三ッ沢上町', '三ッ沢下町', '京急新子安', '京王稲田堤', '向ヶ丘遊園', '新百合ヶ丘', '日本大通り', '神奈川新町', 'たまプラーザ', 'みなとみらい', '元町・中華街', '海の公園柴口', '読売ランド前', '伊勢佐木長者町', '京王よみうりランド') bS <- data.frame(value = c(sapply(range.bS, function(i) unlist(post.list[, i]))), station = factor(rep(station_name, each = n.samples), level=station_name), ymax=rep(0, n.samples), ymin=rep(0, n.samples)) bS.qua <- ddply(bS, .(station), summarize, median=median(value), ymax=quantile(value, prob=0.975), ymin=quantile(value, prob=0.025)) colnames(bS.qua)[2] <- "value" # top 10 bS.qua.desc <- bS.qua[sort.list(bS.qua$value, decreasing=TRUE),] bS.qua.desc.10 <- as.character(bS.qua.desc[1:10, 1]) bS.desc.10 <- filter(bS, station==bS.qua.desc.10[1]| station==bS.qua.desc.10[2]| station==bS.qua.desc.10[3]| station==bS.qua.desc.10[4]| station==bS.qua.desc.10[5]| station==bS.qua.desc.10[6]| station==bS.qua.desc.10[7]| station==bS.qua.desc.10[8]| station==bS.qua.desc.10[9]| station==bS.qua.desc.10[10]) p <- ggplot(bS.desc.10, aes(x=reorder(station, value), y=value, group=station, color=station, ymax=ymax, ymin=ymin)) p <- p + geom_violin(trim=F, fill="#5B423D", linetype="blank", alpha=I(1/3)) p <- p + geom_pointrange(data=bS.qua.desc[1:10,], size=0.75) p <- p + coord_flip() p <- p + ylim(-40, 40) p <- p + labs(x="", y="ランダム効果 [万円/㎡]") p <- p + theme_bw(base_family = "HiraKakuProN-W3") p <- p + theme(axis.text.x=element_text(size=14), axis.title.x=element_text(size=14), axis.text.y=element_text(size=14), legend.position="none") plot(p) # worst 10 bS.qua.asc <- bS.qua[sort.list(bS.qua$value),] bS.qua.asc.10 <- as.character(bS.qua.asc[1:10, 1]) bS.asc.10 <- filter(bS, station==bS.qua.asc.10[1]| station==bS.qua.asc.10[2]| station==bS.qua.asc.10[3]| station==bS.qua.asc.10[4]| station==bS.qua.asc.10[5]| station==bS.qua.asc.10[6]| station==bS.qua.asc.10[7]| station==bS.qua.asc.10[8]| station==bS.qua.asc.10[9]| station==bS.qua.asc.10[10]) p <- ggplot(bS.asc.10, aes(x=reorder(station, value), y=value,group=station, color=station, ymax=ymax, ymin=ymin)) p <- p + geom_violin(trim=F, fill="#5B423D", linetype="blank", alpha=I(1/3)) p <- p + geom_pointrange(data=bS.qua.asc[1:10,], size=0.75) p <- p + coord_flip() p <- p + labs(x="", y="ランダム効果 [万円/㎡]") p <- p + ylim(-40, 40) p <- p + theme_bw(base_family = "HiraKakuProN-W3") p <- p + theme(axis.text.x=element_text(size=14), axis.title.x=element_text(size=14), axis.text.y=element_text(size=14), legend.position="none") plot(p)
*1:東急東横線がいかに人気があるかということは,Home'sやsuumoのランキングで軒並みトップ3にランクインしていることからも見て取れると思います.
*2:もちろん推定自体は普通に行えますけどね.
*3:本当は,駅からの距離や築年数もモデルに組み込みたかったのですが,これらを入れるとうまくモデル推定ができなかったため,今回は除いた結果をお見せします.試行錯誤の過程については,後ほど別エントリでアップする予定です.
*4:平米単価は0未満の値を取ることはないので,厳密には正規分布当てはめは間違っているわけですが,実用上はほぼ問題にならない範囲なので当てはめちゃっています.データの分布をみるに,正規分布よりは対数正規分布の方が当てはまりがいいような気はしますが...
*6:正式名称は横浜高速鉄道みなとみらい21線,だそうです.
*7:なお,その次の湘南新宿ライン宇須というのは,「宇都宮線(東北本線)-新宿ー横須賀線」という経路を通るタイプの湘南新宿ラインのことらしいです.
*8:あと,あざみ野やたまプラーザの近辺は,坂道が多く起伏に富んでいるため,そもそも中古マンションとしてはそれほど魅力的ではないというのもあるかもしれません.