Fundamental Models for Forecasting Elections から考える,日本の選挙における当選者予測方法
参議院選挙が終わったと思ったら今度は都知事選と,まさに選挙の夏ですね.選挙といえば,20時の投票〆切と同時に発表される,マスメディア各社の当選者予測が風物詩です.開票率0%で当確が続々打たれる様は,まさに統計学+社会調査の面目躍如という感じがしますね.各社の当選者予測については,詳細は必ずしも明らかにされていないものの,大枠については様々なところで述べられています.読みやすい記事としては,以下の記事なんかがよくまとまっているのではないでしょうか.
基本としては,RDDベースの社会調査をもとに,過去データに基づいて値の補正や当選確率予測モデルの当てはめを行うことで,高い精度の当確予測を行っている訳ですね.各社は定期的に政党支持率等の調査を行うとともに,選挙期間は頻度を上げて調査を行います.その中で,明確な差があると判断され,かつ出口調査でも傾向が変わらなければ,基本的には20時の時点で当確を打つことが可能になります.こうした選挙調査の手法については,日経リサーチの鈴木さんが書いた「選挙における調査と予測報道」や,朝日新聞社の松田さんが書いた「調査手法転換時の対応と判断 : 2000年総選挙と2001年参院選挙の事例(選挙とOR)」,さらにNHKの仁平さんの「選挙と出口調査」あたりにまとまっています.いずれも結構細かく述べられていて,興味深いです.
さて,こうした社会調査ベースの手法も興味深くはあるのですが,それ以外に当選者予測を行う方法はないのでしょうか.とりあえずCiNiiで日本の論文を探した限り,ほとんど存在しないというのが実情のようです*1 *2.唯一に近く引っかかったのは,「Twitterにおける候補者の情報拡散に着目した国政選挙当選者予測」くらいですが,流石にこれは高い精度を求めた手法という訳でもないので,参考にはならなさそうです.
ということで,もう少し広く探してみたところ,以下の論文が引っかかりました.ということで今回はこの論文の紹介をしたいと思います.
Fundamental Models for Forecasting Elections
論文概要
この論文,正確にはアメリカ経済学会のカンファレンスペーパーとして2013年に発表されているものになります*3.著者はGoogleとMicrosoft Research勤務の経済学者で,基本的には計量経済学の手法が使われています*4.手法としては,アメリカの大統領選,上院選,州知事選などに対して,3ヶ月以上前に手に入るようなマクロデータ等を用いてprobit回帰を行っています.
この論文内の先行研究レビューでは,主に選挙直近に手に入るデータを用いた計量分析や,予測市場に基づいた予測の手法等があげられています.これら手法と比べて,選挙の3ヶ月以上前に当選者を予測することができる,州ごとの予測を既存研究よりも高精度で予測することができる,というのがこの論文の主張になります.
手法
予測する変数は,候補者ごとの得票率と勝利確率の2つになります.これらを,過去の選挙データや経済・政治に関するマクロデータを用いて予測します.得票率については線形回帰,勝率予測はprobit回帰を用いています.各選挙について,州ごとに結果を予測することで,選挙回数に比してサンプル数を増やすことが可能になり,かつ各州の個別要因を考慮することが可能になります.
またこのモデルの特徴は,基本的に民主党と共和党のみを重視したものになっていることです.アメリカの場合は,2大政党制が長く続いており,この形でモデルにしてしまうのが妥当といえます.具体的には,大統領選を予測するモデルの中で,現職大統領が民主党か否かという独立変数を用いていたります(民主党なら1, 共和党なら-1となるダミー変数です).
また,民主党共和党以外の候補については,そのまま独立変数としてモデルに組み込むような荒技を使っています.例えば1968年の大統領選では,アメリカ独立党のジョージ・ウォレス候補がジョージア州・アラバマ州等で勝利を収めていますが,これを「Wallace's vote share in state in 1968 if Southern state and year is 1972」という独立変数として用いています.こうしたことが可能なのも,これらの事象があくまで例外的で,2大政党制が基本的には崩れていないからでしょう.
結果
ここでは,一番精度のよかった大統領選のモデルを示します.線形回帰による得票率予測モデルは,以下の通りです.変数には納得間のあるものがたくさん並んでおり,過去選挙の州ごとの投票率の偏差などは,日本でもそのまま当てはめることができそうにも思います.Wallace, Anderson, Perotあたりは,特別な選挙の影響排除の項目ですね.これらを含んだ結果の調整済決定係数は とそれなりに高い値を示しています.
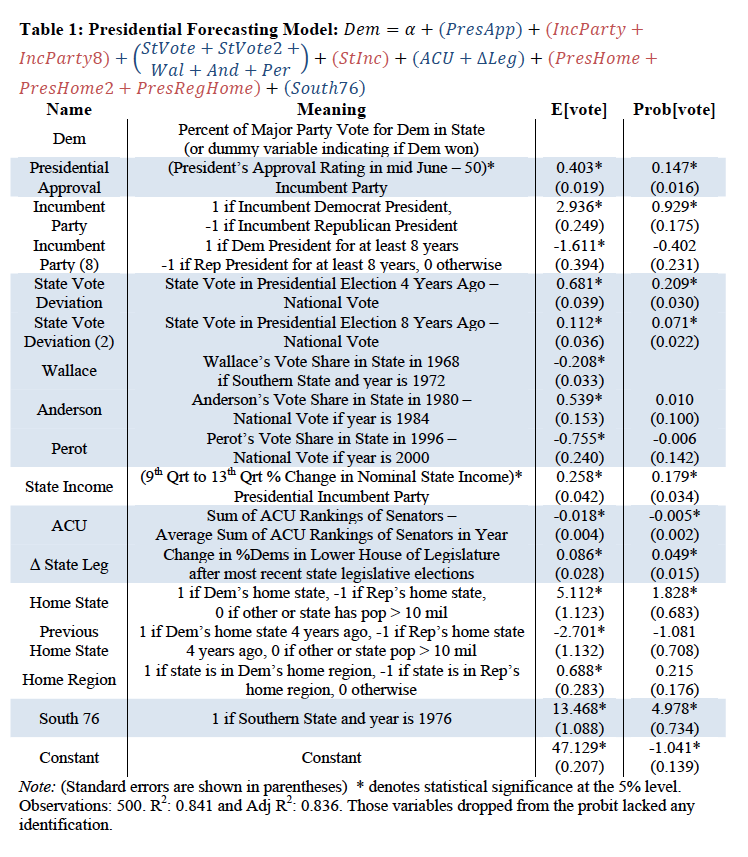
また,結果について,横軸に民主党候補者の予測当選確率/得票率を,縦軸に実際の得票率を示したのが下の図です.たしかに,それなりに綺麗に予測できているといえそうですね.
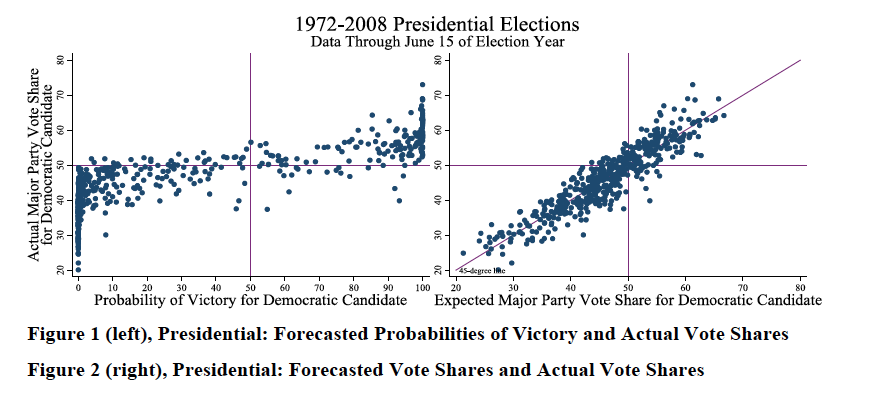
同様に,州知事選や上院選についても,同様の結果がありますが,そちらは論文本体を参照してくださいということで省略します.
雑感
割と綺麗にまとめられた論文でした.さて当然ここで気になるのは,この結果が日本の選挙予測に応用可能なのか,という点です.私自身の感想としては,これだけだと結構厳しいなぁというものです.というのは,日本の選挙は政党の統合や新設が非常に多くあり,かつ政党間の細かい駆け引きや個別事情が入り組んでいます.今回の参院選でも,民主党と維新の会が合流して民進党になりましたが,この時点で既存の予測モデルをそのまま当てはめるのが困難になります.もちろん独立変数に頑張ってパラメタを入れ込むことも可能かもしれませんが,この形を取ると独立変数がそれだけで50個とかできちゃうように思います.
また時代とともに結構党の性格やあり方も変わっていくように思え,stableなモデルをどこまで当てはめてよいものか,結構悩ましいようにも感じます.かといって,動的線形モデルみたいなものを考えれば良いかというと,そもそも選挙という事象は数年に1回しか行われない,非常にサンプル数の限られるドメインです.そのため複雑なモデルを設定することは,それ自体が大きな不確実性を生む要因となってしまいます.そのためちまたで流行のディープラーニングなんかも,選挙に関しては使う機会がなさそうだなぁと思っていたりします.
ということで,詰まるところ既存のマスメディア各社の予測スタイルは,それはそれで最適解なのかもしれないなぁと感じる次第です.でもアカデミアの人たちには,もう少し予測モデル頑張ってほしいなぁと思ったり思わなかったり.
*1:「選挙 予測」みたいなキーワードで検索しても,ほとんど何も引っかからない状態です.
*2:なぜまず日本で探したかというと,選挙制度は各国で非常に大きく異なるため,海外の事例がそのまま日本に当てはまるとは考えにくいからです.
*3:2014年に Fundamental models for forecasting elections at the state level としてElectoral Studies誌にまとめられていますが,例のごとくElsevierの雑誌は有料なので,こちらは呼んでいません.
*4:全然関係ないですけど,アメリカのIT企業が経済学者を研究部門に抱えていたりするの,知を大事にしている感じがしてよいなーと個人的には思っています.